In SSIS gibt es mehrere Möglichkeiten, auf einer Datenmenge einen DISTINCT anzuwenden.
Die einfachsten sind SORT und AGGREGATE.
Diese Transformationen haben jedoch den Nachteil, dass sie sogenannte blocking transformations sind, d.h. dass der nächste Schritt erst durchgeführt wird, nachdem alle Daten durch die SORT– oder AGGREGATE-Transformation gegangen sind.
Dies erhöht natürlich den Speicherbedarf und die Performance.
Die PIVOT-Transformation bietet aber auch diese Möglichkeit und ist dabei nur semi-blocking, d.h. PIVOT arbeitet asynchron, startet aber bereits mit der Ausgabe, auch wenn noch nicht alle Daten verarbeitet wurden. [Ein netter Blog-Eintrag über blocking, semi-blocking etc. findet sich hier: sqlblogcasts.com/blogs/jorg/archive/2008/02/27/…]
Ein Nachteil ist natürlich, dass die PIVOT-Transformation nicht so einfach einzustellen ist, da nur der Advanced Editor zur Verfügung steht, alle Output-Spalten manuell eingetragen werden müssen und sogar die Lineage-ID getippt werden muss. Außerdem muss der Input nach dem Schlüssel sortiert vorliegen – sonst funktioniert PIVOT nicht korrekt. Dies kann aber über ein ORDER BY im SQL leicht erreicht werden.
Es ist zu beachten, dass mindestens eine Spalte ein Pivot-Schlüssel sein muss und eine Spalte die pivotierte Spalte sein muss. Das Ergebnis dieser Spalte muss man allerdings nicht verwenden.
Hier die Einstellungen in einem Beispiel:
Als Abfrage verwenden wir
SELECT YEAR(OrderDate) AS Auftragsjahr, MONTH(OrderDate) AS AuftragsMonat, DAY(OrderDate) AS Auftragstag
FROM Purchasing.PurchaseOrderHeader
ORDER BY 1, 2, 3
auf die AdventureWorks-Datenbank.
Das PIVOT-Element wird wie folgt definiert:
- Tab „Input Columns“: Alle Spalten als READONLY markieren
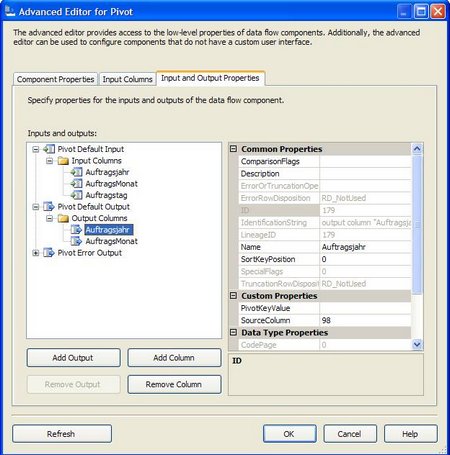
- Tab „Input and Output Properties“ > „Pivot Default Input“ > „Input Columns“:
- Für Auftragsjahr und AuftragsMonat die Eigenschaft „PivotUsage“ auf 1 stellen (soll heißen „Schlüssel-Element“)
- Für Auftragsdatum (diese Spalte brauchen wir nicht mehr) die Eigenschaft „PivotUsage“ auf 2 stellen (soll heißen „diese Spalteninhalte werden pivotiert“ – da aber keine Ziel-Spalten dazu angegeben wurden, passiert das nicht)
- Tab „Input and Output Properties“ > „Pivot Default Output“ > „Output Columns“:
- zwei neue Spalten anlegen „Auftragsjahr“ und „Auftragsmonat“
- Jeweils als Name „Auftragsjahr“ bzw. „Auftragsmonat“ eintragen
- Jeweils als SourceColumn die LineageID der Quell-Spalte eintragen (Diese ersieht man aus den Eigenschaften der entsprechenden Input Column – 1 Zeile über dem Namen)
Hier ein paar Screen Shots zu den Einstellungen… :
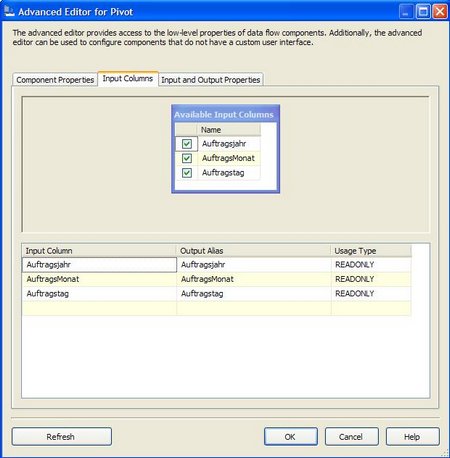
… und dem Ergebnis:
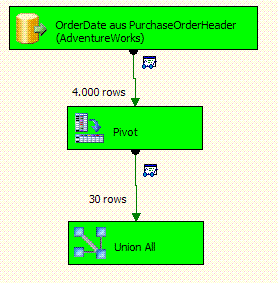
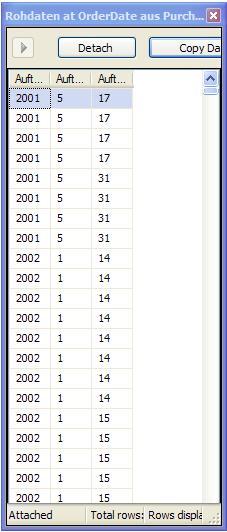
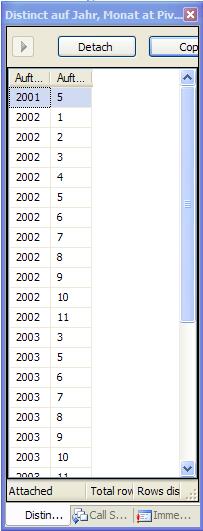
Eine Anmerkung:
Dieser Trick funktioniert nur, wenn man eine Spalte im Recordset hat, die man nicht mehr benötigt – wie in unserem Fall der Auftragstag. Wenn man aber eine solche Spalte nicht zur Verfügung hat, kann über eine abgeleitete Spalte (derived column) leicht eine solche erstellen.
Das dtsx-Paket steht hier zum Download bereit: PivotStattAggregate.zip