Im Web gibt es zwei gute Einträge, wie man entscheidet, ob man beim neuen Analysis Services 2012 das (alte) UDM oder das neue Tabular Model verwenden soll (hervorgegangen aus PowerPivot):
Archiv der Kategorie: MS Analysis Services
Microsoft Analysis Services 2005, 2008, 2008 R2, 2012, 2014, 2016, 2017
Analysis Services Formatierungen (inkl. Excel-Bug bei $)
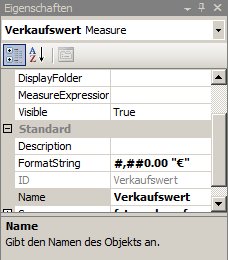
In Analysis Services können „echte“ Measures und berechnete Measures formatiert werden (sprich mit Tausender-Trenner, Nachkommastellen und sonstigen Bezeichnern wie cm oder € verschönert werden). Das erhöht die Lesbarkeit und verhindert Verwechslungen („Ist die Dauer in Stunden oder Minuten?“)
Als Formatstrings können die gängen Bezeichnungen verwendet werden:
- , bedeutet einen Tausendertrenner
- . bedeutet den Dezimalpunkt
- 0 bedeutet, dass diese Stelle immer belegt ist
- # bedeutet, dass diese Stelle angezeigt wird, falls nötig
- In Anführungszeichen („) können beliebige Texte eingegeben werden
So ist #,##0.00 „€“ meine Standardformatierung in €, also zum Beispiel 17,33 € oder 1.522,12 € (auf deutschen Clients).
Interessanter Weise schlägt das BIDS auf deutschen Clients #.##0,00 vor. Das ist aber falsch und wird leider nicht zum Ziel führen.
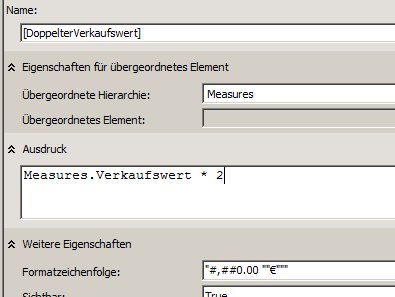
Bei berechneten Measures gilt an sich das gleiche. Allerdings müssen die Strings mit “ umschlossen werden. Falls in dem Formatstring selbst ein Anführungszeichen enthalten ist, muss es verdoppelt werden (wie in der alten VB-Syntax).
Obiger Formatstring ist dann „#,##0.00 „“€“““

Verwendet man Excel als Client, ist ein Bug in Excel zu beachten:
Ich gehe davon aus, dass das Excel ein deutsches Excel ist. Obiger Formatstring funktioniert dann wunderbar. Auch der Formatstring „#,##0.00 „“£“““ funktioniert wunderbar. Allerdings funktioniert „#,##0.00 „“$“““ nicht, statt dessen zeigt Excel € an. Ich erkläre mir das so: Diese Formatierung entspricht der Formatierung „Währung“, die auf deutschen Rechnern eben als € umgesetzt wird. Hier hilft vor oder hinter das Währungssymbol $ ein Leerzeichen einzufügen, also z.B. „#,##0.00″“ $“““
Measure-Meta-Informationen des Cube auslesen: AMO oder ADOMD
Um an die Meta-Informationen des Cubes heranzukommen, gibt es mehrere Zugriffsmöglichkeiten, einmal mit AMO (Analysis Services Management Objects) oder ADOMD (das hauptsächlich für die Ausführung von MDX-Abfragen verwendet wird).
Beigefügt habe ich eine C#-Sollution, die über ADOMD eine CSV-Datei mit allen Measures erzeugt.
Wenn Zeit ist, werde ich diesen Artikel später noch erklären. Vorerst nur soviel:
Der Versuch mit ADOMD auf die Daten zuzugreifen, ist gescheitert, weil dort die berechneten Measures, die ich ebenfalls dokumentieren wollte, nicht einzeln abfragbar sind. Ich habe in einem Blogeintrag von letztem Oktober bereits beschrieben, wie man mit AMO an die MDX-Skripte herankommt. In diesen Skripten gibt es auch CREATE MEMBER-Skripte, die dann durch den Cube in berechnete Measures umgesetzt werden. Wenn man also AMO verwenden will, müsste man diese Skripte parsen (hierzu ein interessanter Blog-Eintrag auf geekswithblogs.net). Wenn man nur an dem Inhalt interessiert ist und die berechneten Measures nicht ändern will, kann man aber darauf getrost verzichten und – wie ich auch in der beigefügten Sollution gemacht habe – stattdessen ADOMD verwenden.
Berechnete Elemente in MDX-Abfragen mit Anwendung in Reporting Services 2005
Lange habe ich gesucht, um ein sinnvolles Beispiel für ein berechnetes Dimensions-Element zu finden (berechnete Measures sind ja ständig zu finden).
Ein Beispiel ist eine Matrix in Reporting Services 2005 (in 2008 ist mit der Tablix ja alles (bzw. vieles) besser).
Ich habe über das Problem bereits zwei Artikel auf sqlservercentral.com veröffentlicht (Reporting Services: Adding extra columns / rows to a matrix und Reporting Services: Read Data from SSAS and SQL Server in One Dataset). Heute möchte ich das Problem auf eine andere Weise lösen.
Nehmen wir an, wir wollen in den Spalten alle Monate sehen und die Summe und einen Planwert und die Differenz zwischen Summe und Planwert. Wenn wir es jetzt schaffen, das ganze in einem MDX-Statement zu laden, so kann auch die Matrix von SQL Server Reporting Services 2005 das anzeigen.
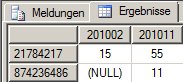
Alle Monate in MDX anzuzeigen, ist einfach. Das Beispiel zeigt je Produkt und Monat den Verkaufswert an (ein konstruiertes, vereinfachtes Beispiel – ich habe sogar auf die Monatsnamen verzichtet und zeige die Monate im Format JJJJMM an):
select non empty [Datum].[Monat].[Monat].members on columns,
non empty [Produkt].[Produkt].[Produkt].members on rows
from [Verkaeufe]
where ([Measures].[Verkaufswert], [Datum].[Jahr].&[2010])liefert:
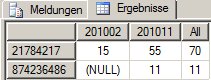
Die Spalte Summe geht auch einfach. Dazu müssen wir den Alle-Member der Attribut-Hierarchie Monat anzeigen:
select non empty {[Datum].[Monat].[Monat].members, [Datum].[Monat].[All]} on columns,
non empty [Produkt].[Produkt].[Produkt].members on rows
from [Verkaeufe]
where ([Measures].[Verkaufswert], [Datum].[Jahr].&[2010])liefert:
Für den Planwert konstruieren wir ein einfache Element der Attribut-Hierarchie Monat, das konstant 10 ist:
with member [Datum].[Monat].[Plan] as 10
select non empty {[Datum].[Monat].[Monat].members, [Datum].[Monat].[All], [Datum].[Monat].[Plan]} on columns,
non empty [Produkt].[Produkt].[Produkt].members on rows
from [Verkaeufe]
where ([Measures].[Verkaufswert], [Datum].[Jahr].&[2010])liefert:
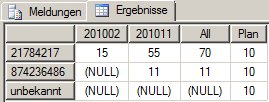
(Die unschöne unbekannt-Zeile kann man natürlich leicht loswerden, aber das ist hier nicht unser Thema)
Das war noch eine leichte Übung. Aber in diesen Berechnungen können wir auch rechnen, wie in jedem MDX. Somit können wir einfach die Differenz anzeigen:
with member [Datum].[Monat].[Plan] as 10
member [Datum].[Monat].[Differenz] as [Datum].[Monat].[All] – [Datum].[Monat].[Plan]
select non empty {[Datum].[Monat].[Monat].members, [Datum].[Monat].[All], [Datum].[Monat].[Plan], [Datum].[Monat].[Differenz]} on columns,
non empty [Produkt].[Produkt].[Produkt].members on rows
from [Verkaeufe]
where ([Measures].[Verkaufswert], [Datum].[Jahr].&[2010])liefert:
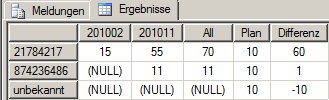
Das finde ich ein sehr schönes Beispiel, wie man berechnete Dimensions-Elemente einsetzt.
Um das ganze in Reporting Services zu verwenden, muss man alles natürlich auf die Zeilen bringen und nur das Measure in den Spalten haben – aber das ist trivial.
Außerdem muss man in der Matrix noch die Sortierung lösen, aber über iif-Berechnungen in dem Sortierungsfeld ist das auch leicht zu lösen.
Snowflake-Schema-Dimensionen mit NULL-Values konfigurieren
Eine Möglichkeit, eine Dimension relational abzubilden, ist ein Snowflake-Schema. In diesem Schema werden Hierarchien so abgebildet, dass jede Hierarchiestufe eine eigene Tabelle besitzt, die durch Foreign Keys verbunden sind.
Probleme können auftreten, wenn nicht bei allen Dimensionselementen alle Ebenen vorhanden sind und deshalb manche Elemente in der Datenbank NULL sind. Diese können über das Setzen der Eigenschaft „NULL Processing“ gelöst werden. Fangen wir aber vorne an.
Ein Beispiel für eine Dimension im Snowflake-Schema seien die Hierarchien Produkt > Warengruppe > Strategisches Geschäftsfeld (SGF) und Produkt > Produktionskennzeichen (hier ein Screenshot des Data Source View):
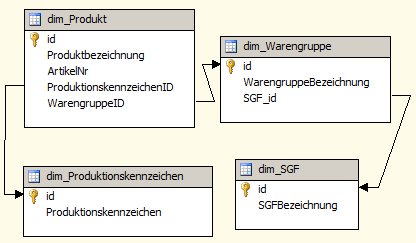
Daraus lässt sich einfach eine Dimension bauen:
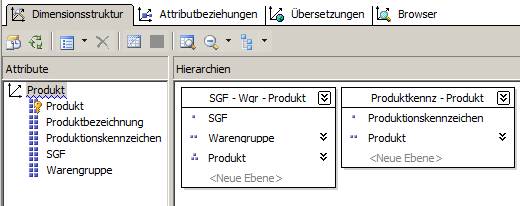
(Zum Vergrößern Bild anklicken)
Die einzelnen Attribute sind so definiert: Die Key-Column ist jeweils die ID-Spalte (also zum Beispiel id aus der Tabelle dim_SGF), die Name-Column jeweils die zugehörige Bezeichnung (z.B. die Tabelle SGFBezeichnung der Tabelle dim_SGF).
In meinem Beispiel kann die Produktionskennzeichen_ID der dim_Produkt NULL sein.
Das hätte jetzt zur Folge, dass – Stand jetzt – die Dimension nicht aufbereitet werden kann:
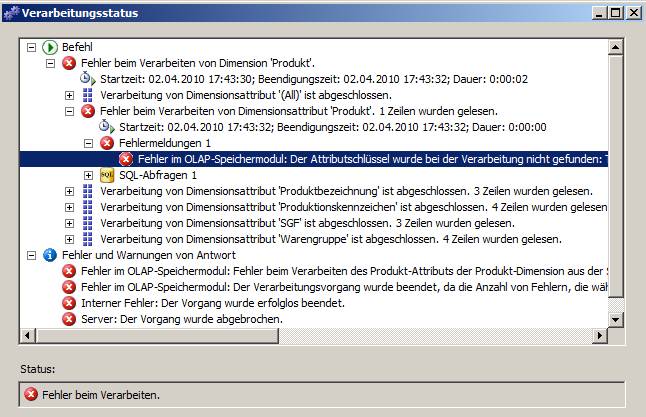
(Zum Vergrößern Bild anklicken)
Die Fehlermeldung im Detail:
Fehler im OLAP-Speichermodul: Der Attributschlüssel wurde bei der Verarbeitung nicht gefunden: Tabelle: dbo_dim_Produktionskennzeichen, Spalte: id, Wert: 0. Das Attribut ist ‚Produktionskennzeichen‘. Fehler im OLAP-Speichermodul: Fehler beim Verarbeiten des Produkt-Attributs der Produkt-Dimension aus der SimpleCube-Datenbank.
Offensichtlich hat der SSAS den NULL-Wert als 0 interpretiert, was er natürlich nicht finden kann.
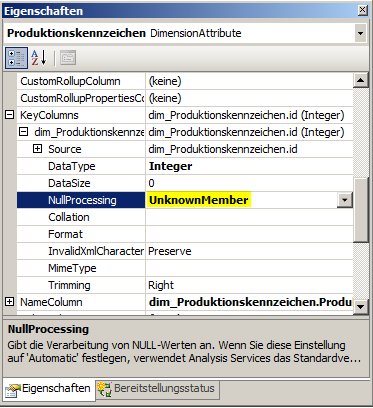
Die Lösung ist:
-
Definieren des Unknown-Members der Dimension als sichtbar mit der Bezeichnung „unbekannt“ (oder wie auch immer)
-
Definieren der Nullprocessing-Eigenschaft der Key Column von Produktionskennzeichen auf „ConvertToUnknown“:
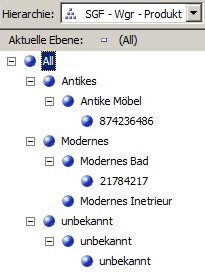
Dann funktioniert die Aufbereitung und die Dimensionen sehen in meinem Beispiel so aus (die Zahlen sind irgendwelche Artikelnummern 🙂 ):
Hierarchie SGF:
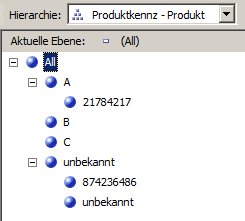
Hierarchie Produktionskennzeichen:
Migration SSAS 2005 > 2008: Class not registered – Fehler
Wenn man eine SSAS-Datenbank von SQL 2005 auf SQL Server Analysis Services 2008 migriert, taucht gerne folgender Fehler auf, der aber eine nicht auf Anhieb durchschaubare Fehlermeldung hat:
Die Migration geht an sich gut. Hat man die SSAS-Datenbank dann aber auf den neuen Server mit SSAS 2008 deployt, so bereitet die Datenbank nicht auf, sondern scheitert mit folgendem Fehler:
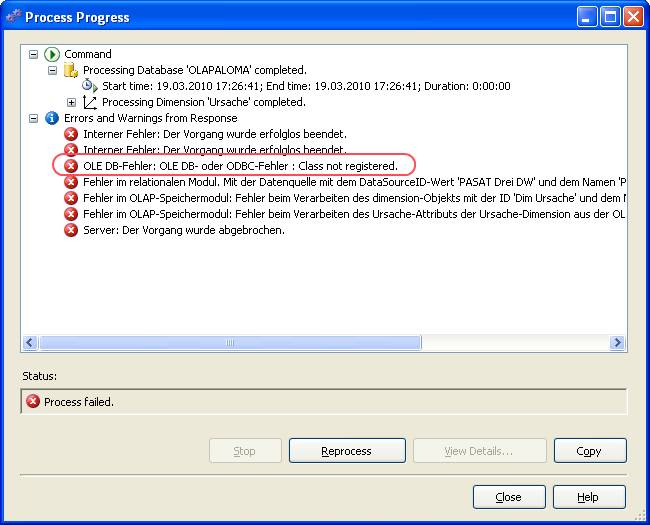
(Zum Vergrößern auf das Bild klicken)
Der Fehler tritt nur auf, wenn die Daten auf dem SQL Server liegen und nach der Migration auf dem Zielserver keine SQL Server 2005-Installation mehr vorhanden ist.
Ursache ist, dass in der Data Source als OLEDB Treiber der SQL Server Native Client in der Version 2005 angegeben ist, aber auf dem neuen Zielserver nicht mehr installiert ist.
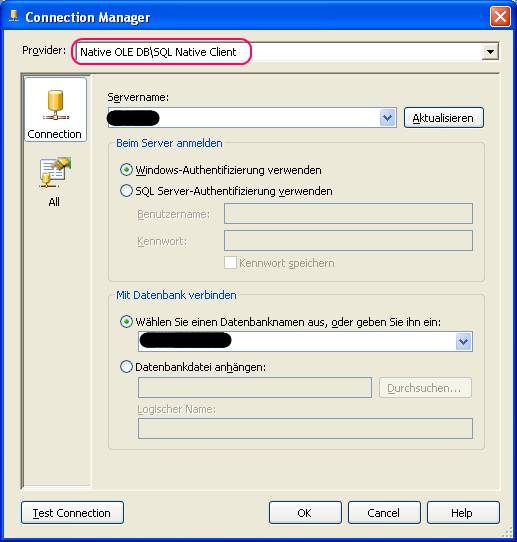
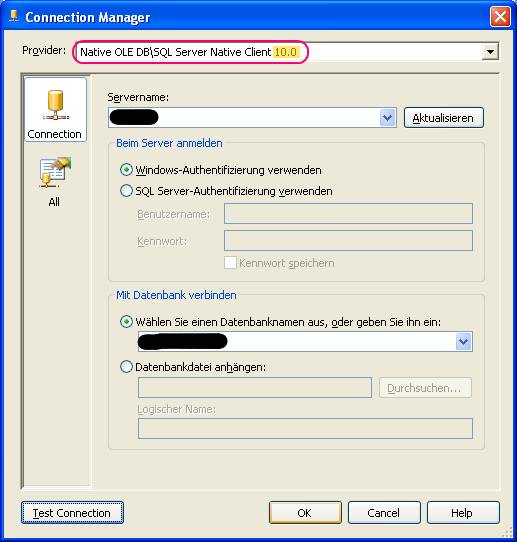
Man kann einfach den Treiber auf die aktuelle Version 2008 (10.0) ändern. Dann funktioniert wieder alles (egal ob die zugrundeliegende Datenbank noch SQL Server 2005 ist oder auch auf SQL 2008 migriert wurde):
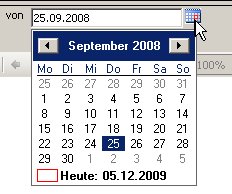
Kalendersteuerelement bei Reports auf Cubes
Reporting Services hat ein Kalendersteuerelement, in dem man Datumswerte einfach eingeben kann, wenn ein Prompt vom Typ Date / Time ist. Heute möchte ich beschreiben, wie man das verwenden kann, wenn man einen Bericht erstellt, der auf einem Analysis Services-Cube basiert. Beim Cube ist (in der Regel) das Problem, dass es zwar eine Zeit-Dimension gibt, diese aber natürlich wie alle Dimensionen einen Member Unique Name (also Key) wie z.B. „[Intervall].[Datum].&[20081012]“ oder „[Intervall].[Datum].&[3207]“ haben. Dies ist offensichtlich ein String und kein DateTime, weswegen beim Standard-Vorgehen der Reporting Services eine Kombobox mit allen Datumswerten erstellt.
Aber hier im Detail das Vorgehen:
Im Wizard zum Erstellen der Abfrage gehen wir wie folgt vor:
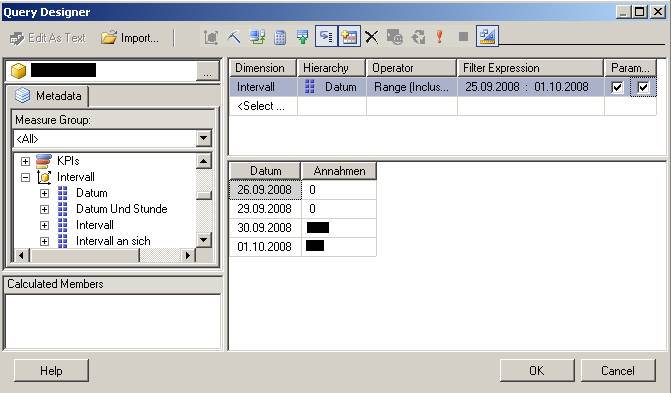
(Zum Vergrößern auf das Bild klicken)
Ich habe einfach eine Kennzahl und das Datum in die Abfrage gezogen und einen Filter auf das Datum gesetzt, wobei ich (wichtig!) die beiden Checkboxen bei den Parametern gesetzt habe.
Bei der Berichtsausführung werden die beiden Parameter über Komboboxen realisiert:
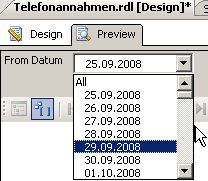
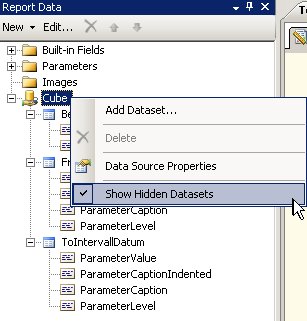
Dazu hat nämlich der Wizard zwei versteckte Data Sets angelegt, die die entsprechenden Werte liefern:
Als nächstes müssen wir das MDX anpassen. (Im Query Designer auf  klicken)
klicken)
Der Wizard hat folgendes MDX erstellt:
SELECT NON EMPTY { [Measures].[Annahmen] } ON COLUMNS, NON EMPTY { ([Intervall].[Datum].[Datum].ALLMEMBERS ) } DIMENSION PROPERTIES MEMBER_CAPTION, MEMBER_UNIQUE_NAME ON ROWS FROM ( SELECT ( STRTOMEMBER(@FromIntervallDatum, CONSTRAINED) : STRTOMEMBER(@ToIntervallDatum, CONSTRAINED) ) ON COLUMNS FROM [<CubeName>]) CELL PROPERTIES VALUE, BACK_COLOR, FORE_COLOR, FORMATTED_VALUE, FORMAT_STRING, FONT_NAME, FONT_SIZE, FONT_FLAGS
Die beiden mit @-benannten Ausdrücke sind die Prompts.
Wir müssen nun den Teil „STRTOMEMBER(@FromIntervallDatum, CONSTRAINED) “ so abändern, dass dort eine Variable vom Typ DateTime eine Rolle spielt. Der Schlüssel eines Datumselements in diesem Fall sieht so aus „[Intervall].[Datum].&[3190]“, wobei die ID die Anzahl der Tage zwischen dem 1.1.2000 und dem betreffenden Tag ist.
Gehen wir nun davon aus, dass wir einen Prompt @von vom Typ DateTime haben, müsste der STRTOMEMBER so aussehen:
STRTOMEMBER(„[Intervall].[Datum].&[“ +cstr( datediff(„d“, DateSerial(2000, 1, 1), @von )) + „]“)
Die DateSerial-Funktion verwende ich hier aus hygienischen Gründen, um keinen Cast von String auf DateTime (der abhängig von der Locale wäre) zu verwenden)
Auf das CONSTRAINED verwende ich, da sonst der Query Designer meckert.
Wenn man selbst natürlich einen anderen Key benutzt, muss dies angepasst werden. Bei einem Key im Format YYYYMMDD, also [Intervall].[Datum].&[20091205], müsste die Formel so sein:
STRTOMEMBER(„[Intervall].[Datum].&[“ +cstr( year(@von) ) + right(„0“ + cstr(month(@von), 2) + right(„0“ + cstr(day(@von), 2) + „]“)
Nun müssen wir noch den Parameter der Abfrage definieren (über  ):
):
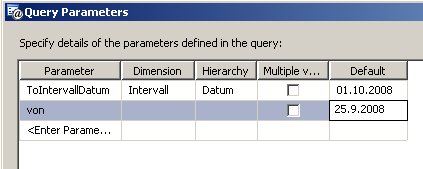
Damit existiert noch nicht der Prompt.
Unter den Eigenschaften des Datasets erscheint der Parameter @von bereits:
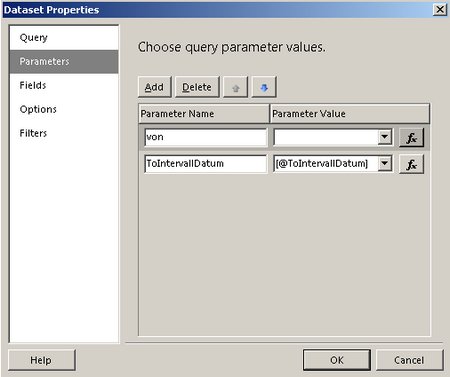
Dort tragen wir in „Parameter Value“ einfach „[@von]“ ein.
Damit wird automatisch ein Report Parameter von angelegt
 , den wir wie folgt bearbeiten: Wir setzen den Datentyp auf Datetime:
, den wir wie folgt bearbeiten: Wir setzen den Datentyp auf Datetime:
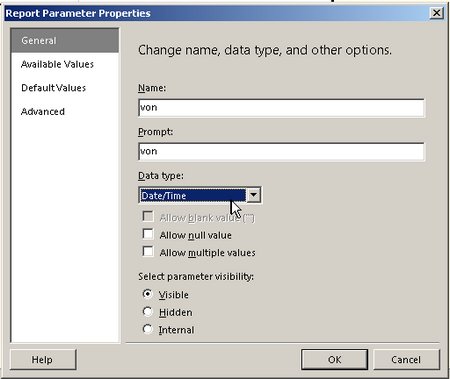
(Außerdem löschen wir den nicht mehr benötigten Prompt „FromIntervallDatum“)
Damit steht jetzt auch hier das Kalendersteuerelement zur Verfügung:
MDX-Skripte eines Cubes über C#-Code anpassen
Zu dem Standard-Aufgaben bei SSAS-Projekten gehören KPIs, wobei Ist- und Planwerte verglichen und danach der Status einer KPI berechnet wird. Heute möchte ich mich auf den Status fokusieren.
Eine normale Regel könnte sein:
- Wenn Ist >= Plan, dann Status grün
- Wenn Ist >= 90% des Plans, dann Status gelb
- Sonst Rot
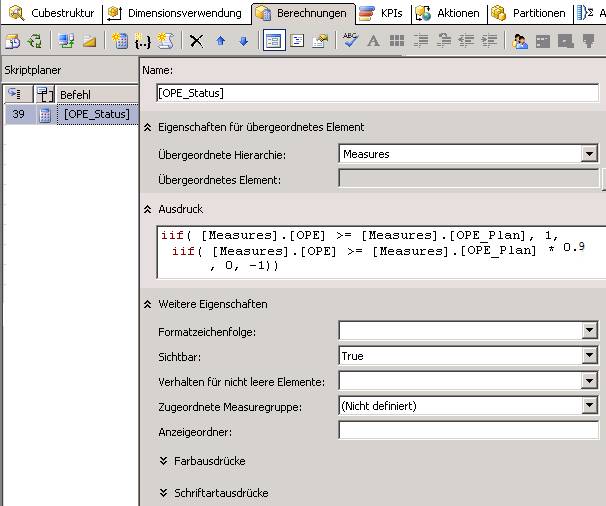
Das sähe im MDX-Skript in etwa so aus:
CREATE MEMBER CURRENTCUBE.[Measures].[OPE_Status]
AS iif( [Measures].[OPE] >= [Measures].[OPE_Plan] , 1,
iif( [Measures].[OPE] >= [Measures].[OPE_Plan] * 0.9, 0, -1)),
VISIBLE = 1;
oder
Dabei steht verabredungsgemäß +1 für grün, 0 für gelb, -1 für rot (wenn es natürlich auch andere Möglichkeiten gibt).
Möglicherweise will man nun aber den Faktor 90% für die Schwelle zwischen Gelb und Rot (oder auch den Schwellwert 100% für die Grenze zwischen Grün und Gelb) dynamisch gestalten – zum Beispiel durch die Eingabe in einer Administrationskonsole. Dann wäre es schön, wenn man dieses MDX dynamisch anpassen könnte.
Deswegen beschreibe ich hier, wie das geht:
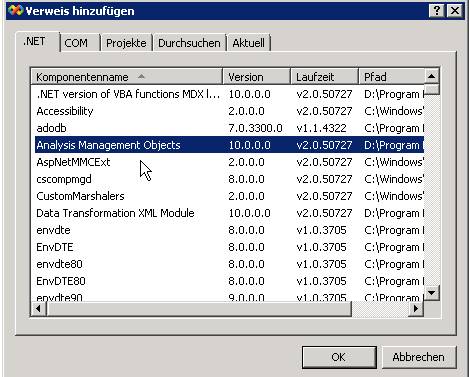
Als erstes muss in C# der Verweis Microsoft.AnalysisServices eingebunden werden. Verwirrenderweise findet man diesen nicht unter Microsoft…, sondern unter Analysis Management Objects (kurz AMO):
Diesen Namespace verwendet man mit
using SSAS = Microsoft.AnalysisServices;
Danach geht es recht einfach:
SSAS.Server server = new SSAS.Server();
try
{
server.Connect(„Data source=<SSAS-Servername>“);
SSAS.Database db = server.Databases.FindByName(„<SSAS-Datenbankname>“);
SAS.Cube cb = db.Cubes.FindByName(„<SSAS-Cubename>“);
}
catch (Exception e) …
Auf die MDX-Skripte hat man dann mit
cb.MdxScripts[0].Commands[0].Text
Zugriff. Diesen String kann man dann auch manipulieren. Damit die Veränderungen auf den Analysis Services gespeichert werden, muss man die Änderungen mit
cb.MdxScripts[0].Update();
speichern.
Ich empfehle die dynamischen MDX-Anteile von den statischen durch Kommentare wie
/*Beginn Statusberechnungen*/n/* Den Text zwischen diesen Markierungen NICHT verändern, da er autogeneriert ist*/n
…
/* Ende Statusberechnungen */
voneinander zu trennen.
Dann kann man auch durch einfache String-Manipulation den zu ändernden Teil herausfischen, ihn ändern und wieder zurückschreiben, ohne den kompletten Cube zu zerstören 🙂
Natürlich muss obiges nicht in einem eigenen C#-Programm programmiert werden, es kann auch als Teil eines SSIS-Pakets verwendet werden.
In einem meiner Projekte verwendete ich einen Data Flow Task, in dem ich die einzelnen Status-Formeln berechnete und in einer Skriptkomponente (als Ziel) die MDX-Skripte in dem Cube aktualisierte. Den Code für die Skriptkomponente habe ich hier als Anlage beigefügt. (Das ist offensichtlich SQL Server 2008, da C# ja erst dann verwendet werden kann 🙂 )
Automatisierung von Analysis Services-Aufgaben über XMLA
Alle Aufgaben, die man im SQL Server Management Studio für den Betrieb eines SQL Server Analysis Services vornehmen kann, können auch über XMLA gesteuert werden.
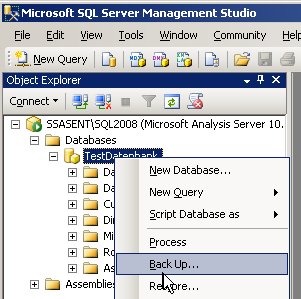
Das gilt zum Beispiel für das Aufbereiten (Verarbeiten, process) von Cubes oder dem Backup von Datenbanken. Ich werde mich heute mit dem Backup einer Analysis Services – Datenbank beschäftigen.
Das Schöne ist, dass wir gar nicht die Syntax der XMLA nachschlagen müssen. Das SQL Server Management Studio erstellt uns nämlich den notwendigen XMLA-Code automatisch (und das gilt für beide Versionen 2005 und 2008). Dazu wählen wir zunächst im Kontextmenü die gewünschte Aktion aus:
Dann startet sich ein Popup-Fenster, in dem wir die gewünschten Einstellungen durchführen, aber nicht auf OK klicken.
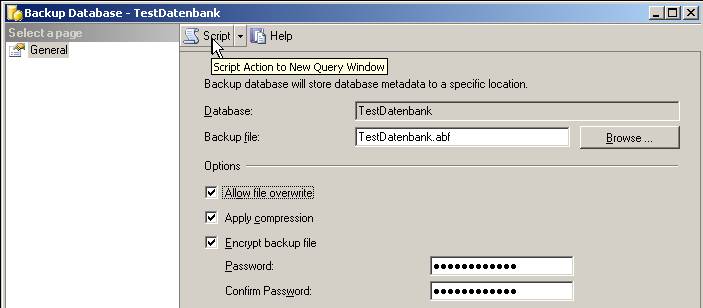
Im oberen Bereich befindet sich eine Script-Button. Wenn man auf diesen klickt, wird das zugehörige XMLA erstellt:
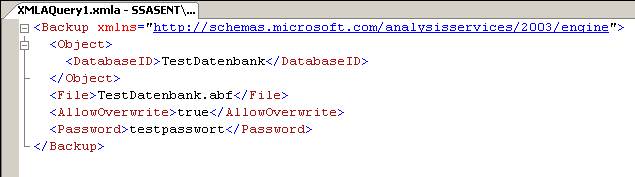
Dies kann man jetzt sogar direkt im SQL Server Management Studio ausführen (Execute!).
Bei Erfolg liefert die Ausführung folgendes Ergebnis:
<return xmlns=“urn:schemas-microsoft-com:xml-analysis“>
<root xmlns=“urn:schemas-microsoft-com:xml-analysis:empty“ />
</return>
Das Problem (auf das wir später noch zurückkommen werden) ist, dass auch bei einem Fehler in der Regel kein Fehler geschmissen wird (bei Analysis Services 2008 kommen manchmal Fehler vor), sondern ein XML zurückgegeben wird, in der die XML-Knoten Exception oder Error oder ähnliches auftauchen. Wie gesagt, dazu später mehr.
Wie können wir nun ein solches XMLA automatisiert (zeitgesteuert) aufrufen?
Die einfachste Möglichkeit ist über den SQL Server Agent. Wir legen dazu einen neuen Job an. Der erste Schritt des neuen Jobs sieht so aus:
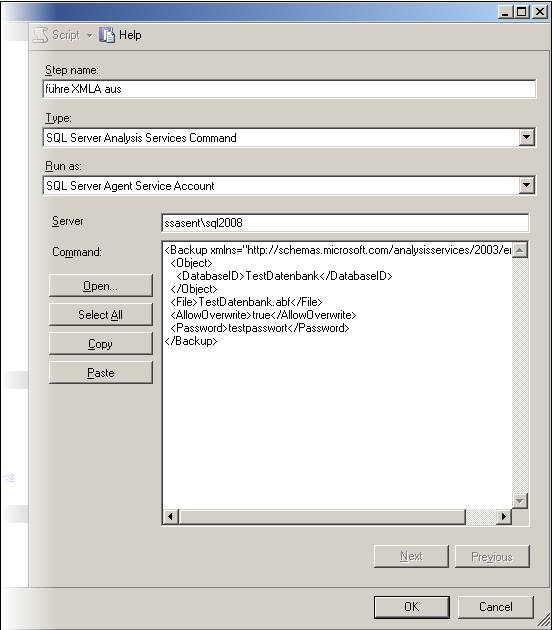
Wie man in obigem Screen Shot sieht, muss als Typ „SQL Server Analysis Services Command“ ausgewählt, als Server dergewünschte SQL Server Analysis Services-Server (hier im Beispiel ssasentsql2008) eingetragen und das XMLA in die große Textbox Command kopiert werden.
Damit kann dieses XMLA im Rahmen eines SQL Server Agent Jobs ausgeführt werden.
Im Log File Viewer kann man nach der Ausführung das ERgebnis der Ausführung wie folgt erkennen:
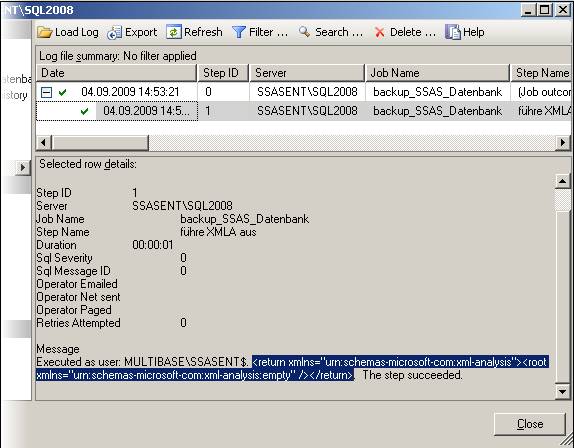
Was ich markiert habe, ist genau das Ergebnis, das wir vorhin auch als Ergebnis bei der Ausführung im SQL Server Management Studio gesehen hatten. Hier erkennt man, dass die Ausführung erfolgreich war, weil das Ergebnis „empty“ ist. Natürlich wird der Job als erfolgreich beendet angezeigt.
Das Problem hierbei ist, dass bei Fehlern bei der Ausführung der Job ebenfalls als erfolgreich abgeschlossen angezeigt wird und die Fehlermeldung nur an dieser Stelle im Log sichtbar ist.
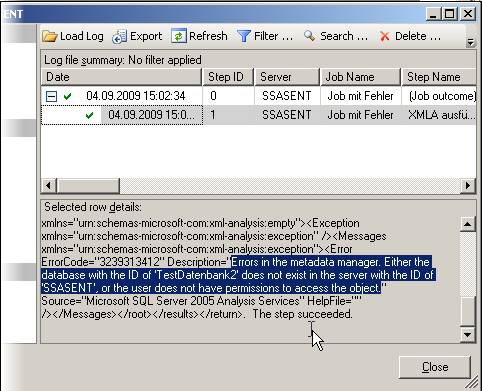
Man erkennt deutlich, dass der Step als erfolgreich markiert ist, aber offensichtlich nicht erfolgreich durchgeführt wurde. Die Fehlermeldung habe ich markiert. (In dem Beispiel handelte es sich um das Aufbereiten einer nicht existenten Datenbank)
Dies ist natürlich sehr ungünstig, da Administratoren auf das Fehlschlagen eines Jobs reagieren können, aber nicht auf irgendwo enthaltene Fehlermeldungen. Deswegen empfehle ich, in produktiven Umgebungen das XMLA nicht direkt im SQL Serevr Agent auszuführen, sondern, wie gleich beschrieben im SSIS. Im SQL Server Agent 2008 scheint dieses Problem behoben zu sein. Wenn man obigen fehlerhaften Job im SQL Server Agent 2008 anlegt (sogar auch wenn man als Ziel des XMLA sogar einen 2005er Analysis Services wählt), wird der Fehler im SQL Server Agent erkannt und sinnvoll protokolliert, wie man in folgendem Screen Shot sehen kann:
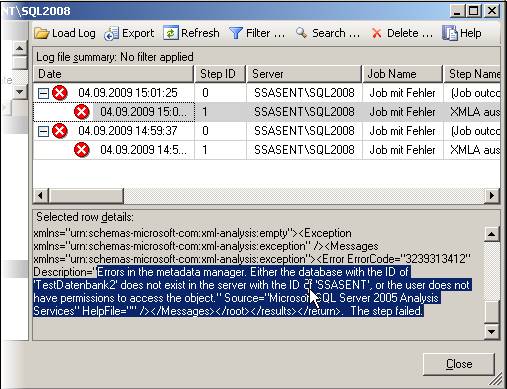
Nun aber zu einer anderen Möglichkeit, das XMLA auszuführen, als Integration Services Package im SSIS:
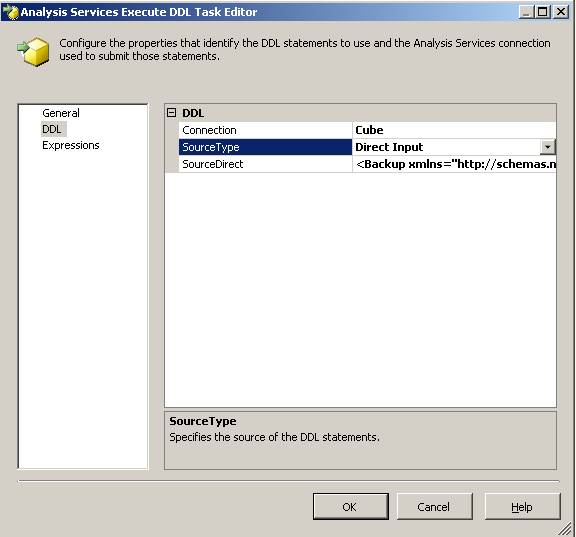
Im Control Flow gibt es dort eine Task mit Titel Analysis Services Execute DDL Task. Diese benötigt eine Cube-Connection und das zu automatisierende XMLA. Das XMLA kann dabei direkt eingegeben oder aus einer Variable oder aus einem File ausgelesen werden. Letzters wird bei großen XMLAs benötigt, da sonst die Größenbeschränkung auf ca. 4000 Zeichen besteht.
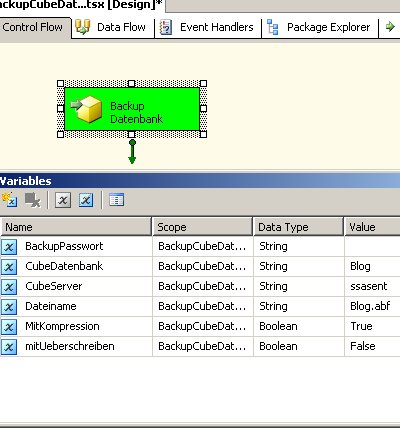
Unter diesem Link habe ich ein einfaches Paket zum Download bereit gestellt, dass nach Eingabe einiger Variablen das XMLA automatisch erstellt (über Expressions der Execute SSAS DDL Task) und dann ausführt. Die Variablen sind im beigefügten Config-File enthalten, so dass Sie das Paket auch einfach über die Anpassungen an dieser Config-Datei steuern können.
Als Variablen werden verwendet:
-
CubeDatenbank: Die SSAS-Datenbank, die gesichert werden soll.
-
CubeServer: Der Name des SSAS-Servers, auf dem sich die zu sichernde Datenbank befindet.
-
Dateiname: Name der zu erstellenden Datei
-
MitKompression: Soll die Datei komprimiert werden? (im Config-File 0 für nein, 1 für ja eintragen)
-
mitUeberschreiben: Soll evtl. eine bereiots existierende Datei überschrieben werden? (im Config-File 0 für nein, 1 für ja eintragen)
-
BackupPasswort: Geben Sie das an, wenn Sie Ihr Backup verschlüsseln wollen, sonst leer lassen (dann wird nicht mit leerem Passwort verschlüsselt 🙂 )
Ganz analog können alle XMLAs mit SSIS ausgeführt werden.
Analysis Services: Zahlen-Formatierung mit Texten (z.B. „min“)
Im Analysis Services kann man natürlich die Formatierung der Measures und berechneten Measures vielfältig gestalten. Die Möglichkeiten gehen aber über die Anzahl der Nachkommastellen hinaus.
Im Beispiel will ich ein Measure, das Zeiten beinhaltet, so formatieren, dass die Zahlen als 17,5 min dargestellt werden. Dadurch ist dem Benutzer klar, dass es sich um Dauer in Minuten handelt.
Bei Measures gibt man als Formatstring an: #,##0.00 min oder #,##0.00″ min“
Bei berechneten Measures gibt man als Formatstring an: „#,##0.00 min“ oder „#,##0.00″“ min“““
[Wegen der Anführungszeichen muss man bei den berechneten Measures aufpassen, da bei einfachen Anführungszeichen ein Syntax Fehler erscheint. Aber wie die Beispiele zeigen, kann man die Anführungszeichen um „min“ herum auch weglassen]
Das Ergebnis in Excel 2007:
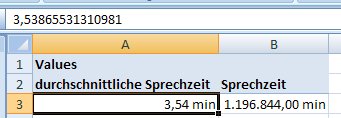
Wie man sieht, stimmt die Formatierung. Und es ist wirklich nur eine Formatierung und kein String, so dass in Excel mit der Zahl auch weiter gerechnet werden könnte.