In einem früheren Blog-Eintrag habe ich beschrieben, wie die Suche im SQL Server Integration Services (im Standard) abhängig von der Groß- und Kleinschreibung ist. Das liegt daran, dass der Cache im Integration Services binär angelegt werden, so dass „Martin“, „martin“ und „MARTIN“ 3 unterschiedliche ELemente sind, wohingegen bei einem SELECT DISTINCT Vorname FROM Personen dies (in der Standard-Collation) nur als einen Wert zurückliefern würde.
Dieses Phänomen tritt aber natürlich nicht nur bei Groß- und Kleinschreibung auf, sondern bei allen Strings, die laut Collation gleich sind.
Damit führt das Standard-Szenario nicht zum gewünschten Ergebnis, wenn ich zum Beispiel Vornamen in eine Dimensionstabelle umsetzen will:
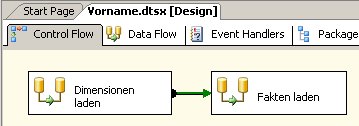
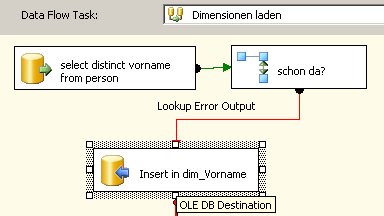
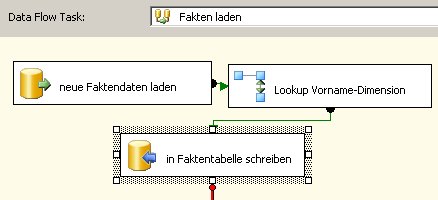
In meinem Beispiel habe ich die Personen-Tabelle wie folgt gefüllt:
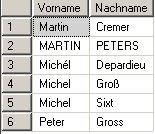
Auf der Nachnamen-Spalte habe ich die Standard-Collation (SQL_Latin1_General_CP1_CI_AS) verwendet, die Vornamen-Spalte habe ich so eingestellt, dass auch Akzente ignoriert werden (Collation Latin1_General_CI_AI) (OK, das ist ein bisschen gestellt, aber in der Praxis hatte ich einen ähnlichen Fall).
Somit liefert select distinct vorname from person:
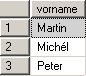
und select distinct nachname from person:
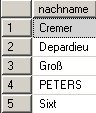
Man beachte, dass bei der Standard-Collation ß wie ss behandelt wird.
Nun ist klar, dass beim Lookup nach Vorname im Faktenimport nicht alle Vornamen einen Treffer liefern und somit das ETL einen Fehler schmeißt.
Außerdem ist es vermutlich nicht sinnvoll, dass Michel und Michél gleiche Vornamen sind. Deswegen beitet es sich in diesem Fall an, dass alle unterschiedlichen Schreibweisen der Vornamen auch unterschiedliche Dimensionselemente werden. Dazu kann man im Dimensions-SELECT statt „SELECT DISTINCT Vorname FROM Personen“ besser „SELECT DISTINCT vorname COLLATE Latin1_General_BIN as Vorname from person“ verwendet. Damit instruiert man den SQL Server die binäre Collation zu verwenden und somit sind beim SQL Server selbst die einzelnen Vornamen nicht mehr gleich – und schon geht’s.
Eine andere Alternative wäre gewesen, über eine Funktion Strings, die gleich sein sollen, in einen eindeutigen String zu überführen (wie in meinem letzten Blog-Eintrag mit UPPER()). Bei Akzenten ist das aber nicht so einfach.
Eine weitere Alternative ist, den Lookup nicht mit vollem Cache zu machen, was aber negative Auswirkungen auf die Performance hat. Also könnte man auch zuerst einen Lookup mit vollem Cache und im Fehlerfall einen nachgelagerten Lookup ohne Cache ausführen. Im zweiten Lookup kann man dann über die Collation genau definieren, welche Strings gleich sein sollen und welche nicht.
In einem solchen Fall muss man also auf jeden definieren, welche Strings im DWH als gleich angesehen werden sollen. Über die COLLATION kann man das – wie gezeigt – sehr fein einstellen.
Natürlich sind solche Szenarien selten, da in der Regel nicht beliebige Freitextwerte in einer Dimension vorkommen – aber, wie in meinen Projekten geschehen, ab und zu gibt es dann doch solche Fälle.