Wir hatten einen Cube (tabular model), das wir ausreichend getestet hatten. Wir hatten auch Filter (Slices in Power BI bzw. Filter in Excel Pivot) auf das Attribut Land getestet.
Als wir aber nun eine Rolle anlegten, die auf ein Land filterte, funktionierten unsere Berichte nicht mehr für diese Personen.
Da mich das sehr überrascht hat, möchte ich hier die Details beschreiben.
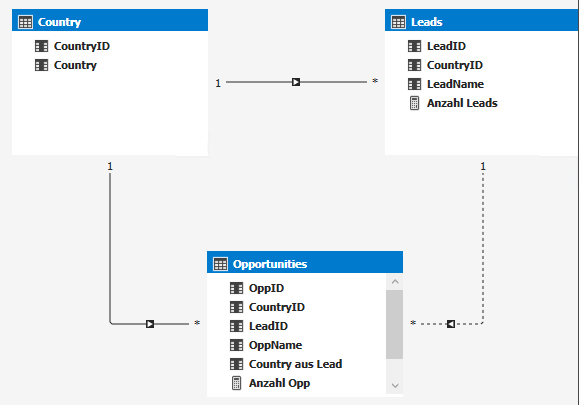
Beispiel-Cube
Wir erstellen einen Cube mit 3 Tabellen:
Country
Lead
Opportunity
Leads und Opportunities haben jeweils ein Land – und sind damit mit der Tabelle Country verbunden.
Opportunities können aus Leads hervorgehen. Dafür haben Opportunities eine LeadID, die aber leer sein kann. Außerdem kann das Land des Leads unterschiedlich vom Land der daraus generierten Opportunity sein.
Da diese Relationen einen Zirkel bedeuten würden, ist die Beziehung zwischen Lead und Opportunity auf inaktiv gesetzt – und kann dann über USERELATIONSHIP() in einem Measure verwendet werden.
Datenmodell mit aktiven und inaktiven Verbindungen
Als Measures definieren wir:
Anzahl Leads:=COUNTROWS(Leads)
Anzahl Opp:=COUNTROWS(Opportunities)
Anzahl Opportunities via Leads:=CALCULATE(COUNTROWS(Opportunities), USERELATIONSHIP(Leads[LeadID],Opportunities[LeadID]))
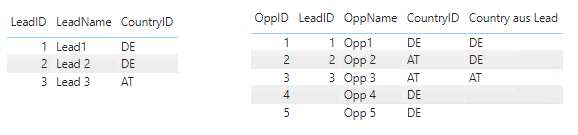
In den Tabellen haben wir folgende Beispieldaten:
Beispieldaten
Somit ergeben sich für die Measures folgende Ergebnisse:
Filter
Measure
Wert
IDs
ohne
Anzahl Leads
3
1,2,3
ohne
Anzahl Opp
5
1,2,3,4,5
ohne
Anz Opp via Lead
5
1,2,3,4,5
Deutschland
Anzahl Leads
2
1,2
Deutschland
Anzahl Opp
3
1,4,5
Deutschland
Anz Opp via Lead
2
1,2
Österreich
Anzahl Leads
1
3
Österreich
Anzahl Opp
2
2,3
Österreich
Anz Opp via Lead
1
3
Ergebnisse
Soweit ist das wenig überraschend.
Wenn wir jetzt aber eine Rolle mit Row Level Security – Filter =Country[Country]="Deutschland" definieren, so hätte ich erwartet, dass wir die Werte erhalten, die in obiger Tabelle unter Deutschland stehen.
Das stimmt auch für die beiden ersten Measures. Allerdings gibt das Measure „Anzahl Opportunities via Leads“ folgenden Fehler zurück:
Error: The UseRelationship() and CrossFilter() functions may not be used when querying ‚Opportunities‘ because it is constrained by row-level security defined on ‚Leads‘ or related tables.
Das finde ich sehr verblüffend. Eigentlich halte ich das für einen Bug. Da er aber so (mindestens) seit SSAS 2016 enthalten ist, gehe ich davon aus, dass Microsoft das nicht so sieht.
Deswegen sollte man mit USERELATIONSHIP() sehr sparsam umgehen, da sich dadurch Nebeneffekte auf Row Level Security ergeben.
(Nur als Randbemerkung: Bei meinem Kunden hatte ich eine andere Fehlermeldung (ambiguous paths). Ich weiß nicht, ob es am Patch-Level lag oder ich die Situation nicht 100% genau nachstellen konnte)
In meinen Projekten kommt es natürlich oft vor, dass man Datumsdimensionen benötigt.
Dazu verwende ich Stored Functions im SQL Server, um die Datumswerte mit allen gewünschten Attributen (wie Wochentag, Monat, Kalenderwoche, etc.) an den Analysis Services-Dienst weiter zu geben. Ich will das hier beschreiben, weil seit SSAS 2017 der Aufruf von Stored Functions gar nicht mehr so offensichtlich ist (wenn man die depracted Data Sources nicht verwenden will).
Das Vorgehen ist wie folgt:
Ermittle die Datumswerte, die die Datumsdimension enthalten soll. In der Regel ist das entweder ein Zeitraum oder distinkte Werte (z.B. bei einer Dimension, in der der Datenstand ausgewählt werden kann)
Liefere zu den ermittelten Datumswerten alle Attribute wie Wochentag, Monat, Kalenderwoche, etc.)
Gib diese Daten an den SSAS weiter
Wir benutzen hier bewusst einen getrennten Ansatz, erst die anzeigenden Datumswerte zu ermitteln und dann dazu die Attribute zu erzeugen. Dadurch erreichen wir die höchst mögliche Flexibilität. Man könnte zum Beispiel folgendes machen:
Wir nehmen alle Datumswerte vom Minimum der auftretenden Werte bis zum Maximum
Da aber Fehleingaben enthalten sind, und wir nicht alle Datumswerte vom 1.1.2000 bis 1.1.3000 in unserer Dimension haben wollen, nehmen wir nur die Datumswerte vom Minimum bis zum Ende nächsten Jahres und alle weiteren DISTINCTen Werte, die vorkommen.
Wir gehen so vor:
Als erstes legen wir einen Type an, der eine Liste von Datumswerten halten kann:
CREATE TYPE [dbo].[typ_Datumswerte] AS TABLE(
[datum] [date] NOT NULL,
PRIMARY KEY CLUSTERED
(
[datum] ASC
)WITH (IGNORE_DUP_KEY = OFF)
)
GO
In eine Variable dieses Datentyps können wir nun beliebige Datumswerte speichern. Wenn man zum Beispiel eine distinkte Menge an Datumswerten aus einer Faktentabelle speichern will, kann man das so machen:
DECLARE @d AS typ_Datumswerte
INSERT INTO @d SELECT DISTINCT Datum FROM Fakt_Auftragsbestand
Meistens benötigt man aber einen ganzen Zeitraum an allen möglichen Datumswerten. Dafür habe ich eine triviale Stored Function geschrieben:
-- =============================================
-- Author: Martin Cremer
-- Create date: 07.07.2015
-- Description: liefert alle Tage eines bestimmten Zeitraums
-- =============================================
CREATE FUNCTION [dbo].[f_alle_Datumswerte]
(
@von date,
@bis date
)
RETURNS
@tab TABLE
(
datum date
)
AS
BEGIN
while @von <= @bis
begin
insert into @tab select @von
set @von = dateadd(d, 1, @von)
end
RETURN
END
GO
Um einen ganzen Zeitraum nun in eine Variable des oben definierten Typs zu schreiben, geht man so vor:
DECLARE @d AS typ_Datumswerte
INSERT INTO @d
SELECT * FROM dbo.f_alle_Datumswerte(
(SELECT min(Datum) FROM Fakt_Auftragsbestand),
(SELECT max(Datum) FROM Fakt_Auftragsbestand)
)
Damit hätten wir den ersten Punkt erledigt. Kommen wir nun dazu, alle benötigten Attribute zu ermitteln. Dafür gibt es ein paar Hilfsfunktionen, deren 1. Version ich sogar am 1.1.2009 hier schon im Blog veröffentlicht hatte, und eine Funktion, die alles zusammenfasst. Zunächst die Hilfsfunktionen (auf die heutige Zeit angepasst, in der der SQL Server nativ die deutsche ISO-Woche ermitteln kann):
-- =============================================
-- Author: Martin Cremer
-- Create date: 16.8.2006
-- Description: ermittelt aus dem Datum den Wochentag (unabhängig von SET DATEFIRST): 1=Montag - 7=Sonntag
-- =============================================
CREATE FUNCTION [dbo].[getWochentag]
(
@dat date
)
RETURNS int
AS
BEGIN
DECLARE @Result int
SELECT @Result = (datepart(dw, @dat) - 1 + @@datefirst -1) % 7 +1
RETURN @Result
END
GO
CREATE FUNCTION [dbo].[getKW_Jahr](@h as date)
returns int
as
begin
return case
when datepart(isowk, @h)>50 and month(@h) = 1 then year(@h)-1
when datepart(isowk, @h)=1 and month(@h) = 12 then year(@h)+1
else year(@h)
end
end
GO
CREATE FUNCTION [dbo].[getKW_Woche](@h as date)
returns int
as
begin
return datepart(isowk, @h)
end
GO
Die geradlinige zusammenfassende Funtkion sieht dann so aus:
-- =============================================
-- Author: Martin Cremer
-- Create date: 07.07.2015
-- Description: liefert zu den übergebenen Datumswerten alle Attribute
-- =============================================
CREATE FUNCTION [dbo].[f_Datumsattribute]
(
@datumswerte as dbo.typ_Datumswerte readonly
)
RETURNS
@Ergebnis TABLE
(
Datum date NOT NULL,
[KW_ID] INT NOT NULL,
[KW_Jahr] SMALLINT NOT NULL,
[KW] NVARCHAR(10) NOT NULL,
[KW_Nr] SMALLINT NOT NULL,
[Monat_ID] INT NOT NULL,
[Monat_OhneJahr_ID] TINYINT NOT NULL,
[Monat] NVARCHAR(8) NOT NULL,
[Monat_OhneJahr] NVARCHAR(3) NOT NULL,
[Jahr] SMALLINT NOT NULL,
[Quartal_ID] SMALLINT NOT NULL,
[Quartal_OhneJahr_ID] TINYINT NOT NULL,
[Quartal_OhneJahr] NVARCHAR(50) NOT NULL,
[Quartal] NVARCHAR(50) NOT NULL,
[Wochentag_ID] int NOT NULL,
[Wochentag] nvarchar(20) NOT NULL,
[Wochentag_Kürzel] nvarchar(2) NOT NULL
)
AS
BEGIN
INSERT INTO @Ergebnis
(Datum, [KW_ID], [KW_Jahr], [KW], [KW_Nr], [Monat_ID], [Monat_OhneJahr_ID], [Monat], [Monat_OhneJahr], [Jahr],
[Quartal_ID], [Quartal_OhneJahr_ID], [Quartal_OhneJahr], [Quartal], [Wochentag_ID], [Wochentag], [Wochentag_Kürzel])
SELECT
x.datum,
x.KW_Jahr * 100 + x.KW /* 201501 für KW 01/2015*/,
x.KW_Jahr /*2015*/,
'KW ' + RIGHT('0' + CONVERT(NVARCHAR(2), x.KW), 2) + '/' + CONVERT(NVARCHAR(4), x.KW_Jahr) /* KW 01/2015*/,
x.KW /*1*/,
x.jahr * 100 + x.Monat /* 201501 für Jan 2015 */,
x.monat /* 1 */,
monate.monatsname + ' ' + CONVERT(NVARCHAR(4), x.jahr) /* Jan 2015 */,
monate.monatsname /* Jan */,
x.jahr,
x.jahr * 10 + x.quartal /* 20151 für Q1 2015 */,
x.quartal /* 1 */,
'Q' + CONVERT(NVARCHAR(1), x.quartal) /* Q1 */,
'Q' + CONVERT(NVARCHAR(1), x.quartal) + ' ' + CONVERT(NVARCHAR(4), x.jahr),
x.wochentagID,
Wochentage.Wochentagname,
Wochentage.Wochentagkurz
FROM
(SELECT [dbo].[getKW_Jahr](d.datum) AS KW_Jahr, [dbo].[getKW_Woche](d.datum) AS KW,
MONTH(d.datum) AS monat,
datepart(QUARTER, d.datum) AS quartal,
year(d.datum) AS jahr,
[dbo].[getWochentag](d.datum) as wochentagID,
d.datum
FROM @datumswerte as d) AS x
LEFT JOIN
(SELECT 1 AS monat, 'Jan' AS Monatsname UNION ALL
SELECT 2, 'Feb' UNION ALL
SELECT 3, 'Mär' UNION ALL
SELECT 4, 'Apr' UNION ALL
SELECT 5, 'Mai' UNION ALL
SELECT 6, 'Jun' UNION ALL
SELECT 7, 'Jul' UNION ALL
SELECT 8, 'Aug' UNION ALL
SELECT 9, 'Sep' UNION ALL
SELECT 10, 'Okt' UNION ALL
SELECT 11, 'Nov' UNION ALL
SELECT 12, 'Dez' ) AS monate
ON x.monat = monate.monat
LEFT JOIN
(SELECT 1 as WochentagID, 'Montag' Wochentagname, 'Mo' Wochentagkurz UNION ALL
SELECT 2, 'Dienstag', 'Di' UNION ALL
SELECT 3, 'Mittwoch', 'Mi' UNION ALL
SELECT 4, 'Donnerstag', 'Do' UNION ALL
SELECT 5, 'Freitag', 'Fr' UNION ALL
SELECT 6, 'Samstag', 'Sa' UNION ALL
SELECT 7, 'Sonntag', 'So' ) as Wochentage
ON x.wochentagID = Wochentage.WochentagID
RETURN
END
GO
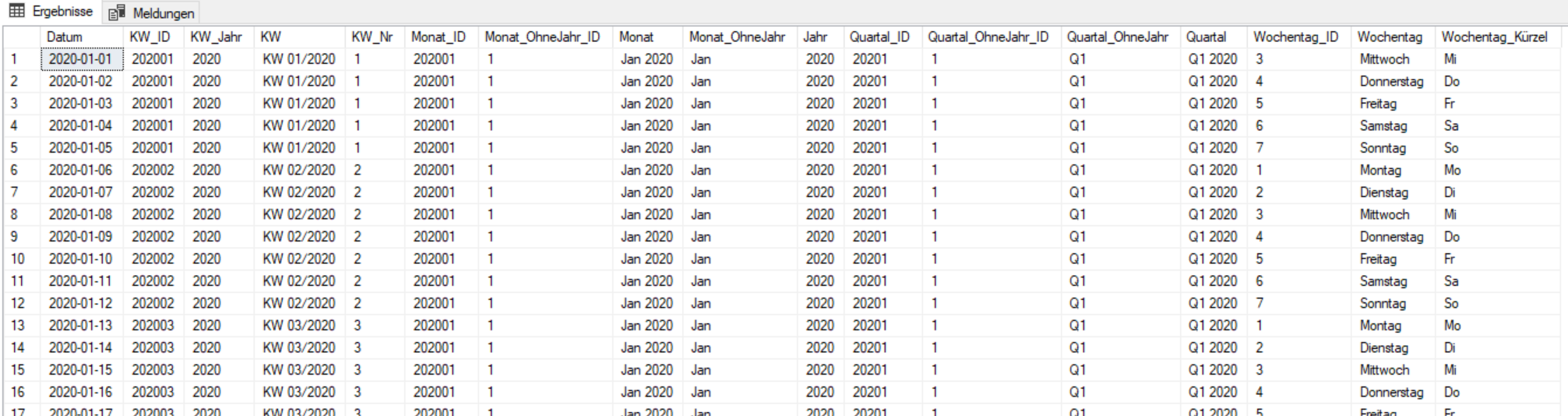
Somit kann man nun obige Ermittlung der gewünschten Datumswerte um die Ausgabe der Attribute erweitern, also zum Beispiel so:
declare @tage as [dbo].[typ_Datumswerte]
INSERT INTO @tage select * from dbo.f_alle_Datumswerte(convert(date, '1.1.2020', 104), convert(date, '31.12.' + convert(nvarchar(4), year(getdate())), 104))
select * from dbo.f_Datumsattribute(@tage)
Das Ergebnis sieht dann so aus:
Ergebnis Datumswerte
Nun müssen wir dieses SQL nur noch im SSAS ausführen lassen. Seit viele Neuerungen aus PowerBI in das Produkt SSAS einfließen, hat sich auch die Art und Weise geändert, wie man das Ergebnis von SQL-Statements im SSAS einbinden kann. Früher war es ja ganz einfach ein SQL-Statement anstelle einer Tabelle (bzw. View) zu verwenden, heute muss man wie folgt vorgehen [Die Idee dazu fand ich in Chris Webbs sehr gutem BI-Blog (hier).]:
Wenn man in Visual Studio eine neue Tabelle hinzufügt, wird im Hintergrund M-Code erzeugt, der in etwa so aussieht:
let
Source = #"SQL/<host>;<Datenbank>",
meineTabelle = Source{[Schema="dbo",Item="Beispiel"]}[Data]
in
meineTabelle
Über die Properties der Tabelle > Quelldaten > (Zum Bearbeiten klicken) kann man diesen Code einsehen.
Zu verstehen ist der Code ja ganz leicht: Über Source wird die SQL-Connection auf dem Host <host> und Datenbank <Datenbank> geöffnet. Daraus wird im obigen Beispiel die Tabelle dbo.Beispiel geladen.
Wenn wir nun obiges SQL ausführen wollen, fügen wir zunächst auf den normalen Weg im UI eine neue Tabelle hinzu (welche ist vollkommen egal). Danach bearbeiten wir dieses M-Statement zu
let
Source = #"SQL/<Host>;<Datenbank>",
Entlassungsdatum = Value.NativeQuery(
Source,
"declare @tage as [dbo].[typ_Datumswerte]
INSERT INTO @tage select * from dbo.f_alle_Datumswerte(convert(date, '1.1.2020', 104), convert(date, '31.12.' + convert(nvarchar(4), year(getdate())), 104))
select * from dbo.f_Datumsattribute(@tage)"
)
in
Entlassungsdatum
Entscheidend ist also die Änderung von Source{}[Data] zu Value.NativeQuery().
In einem Projekt hatte ich neulich die Anforderung zu kontrollieren, ob die im Integration Services Katalog auf dem SQL server enthaltenen SSIS-Pakete aktuell sind.
Bei dem Kunden gab es sehr viele Projekte und noch mehr Pakete. Dazu wurden nicht nur die Projekte als ganzes deployt (via ispac) sondern auch einzelne Pakete auch separat. Deswegen reichte es nicht die aktuelle Projekt-Version zu betrachten.
Statt dessen habe ich folgendes Statement verwendet:
use SSISDB;
with e as (
select
p.name,
xs.execution_path
,cast(xs.start_time as datetime2(0)) as start_time
,x.project_version_lsn
,p.version_build
from internal.executables x
join internal.executable_statistics xs on x.executable_id = xs.executable_id
join internal.packages p
on x.project_id = p.project_id
and x.project_version_lsn = p.project_version_lsn
and x.package_name = p.name
where
x.executable_name + '.dtsx'= x.package_name
)
select e.name, e.start_time, e.version_build
from e
where e.start_time = (select max(start_time) from e e2 Where e2.name = e.name)
order by 1
Dieses Statement liefert mir zu allen Paketen den letzte Ausführungs-Zeitstempel und die Version Build dieses Laufs. Da (bei uns) sicher war, dass die zuletzt ausgeführte Version auch die aktuelle Version war, konnte ich so die Überprüfung vereinfachen.
Meine Erfahrungen in der Business Intelligence Welt