Fehlersituation
In meinem aktuellen Projekt lesen wir aus Dynamics CRM 365 Daten in unser Data Warehouse, das wir unter Azure gebaut haben. Wir hatten dabei ein Problem: In einigen Tabellen gibt es Spalten, die in vielen Zeilen nicht gefüllt sind. Wir hatten identische Testdatensätze, die an zwei unterschiedlichen Tagen nach CRM importiert wurden (durch ein anderes Team). Beim Laden der Daten fiel uns auf, dass an einem Tag eine Spalte leer blieb, obwohl sie am Abzug am Tag zuvor manchmal Werte enthalten hatte – und sich in der Quelle nichts geändert hatte.
Das Ergebnis unserer Suche und die Fehlerbehebung möchte ich hier kurz beschreiben.
Einstieg
Als Einstieg empfehlen sich diese beiden Seiten: Microsoft-Dokumentation und dieser SQL Server Central-Artikel. Aber es gibt natürlich noch etliche Artikel im Netz.
Interessanter Weise enthält der Microsoft-Artikel folgende Stelle – markiert als wichtig (ca. in der Mitte des Artikels):
- Wenn Sie Daten aus Dynamics kopieren, ist die explizite Spaltenzuordnung aus Dynamics zur Senke optional. Es wird jedoch dringend zu der Zuordnung geraten, um ein deterministisches Kopierergebnis sicherzustellen.
- Wenn ein Schema in Data Factory in der Erstellungsbenutzeroberfläche importiert wird, wird auf das Schema rückgeschlossen. Dies erfolgt, in dem die obersten Zeilen aus dem Ergebnis der Dynamics-Abfrage gesamplet werden, um die Liste der Quellspalten zu initialisieren. In diesem Fall werden Spalten ohne Werte in den obersten Reihen ausgelassen. Dasselbe Verhalten gilt für Kopiervorgänge, wenn keine explizite Zuordnung vorliegt. Sie können Spalten überprüfen und weitere zur Zuordnung hinzufügen. Diese Spalten werden auch während der Laufzeit des Kopiervorgangs berücksichtigt.
Hier ist also genau unser Problem beschrieben: Wenn eine Zeile viele NULL-Werte enthält, kann es (nicht deterministisch) passieren, dass die Inhalte der Spalte nicht übertragen wird, wenn kein Schema definiert ist.
Unser ursrünglicher Code
Unsere Einstellungen der Copy-Aktivität sahen so aus:
Zunächste die Quelle:
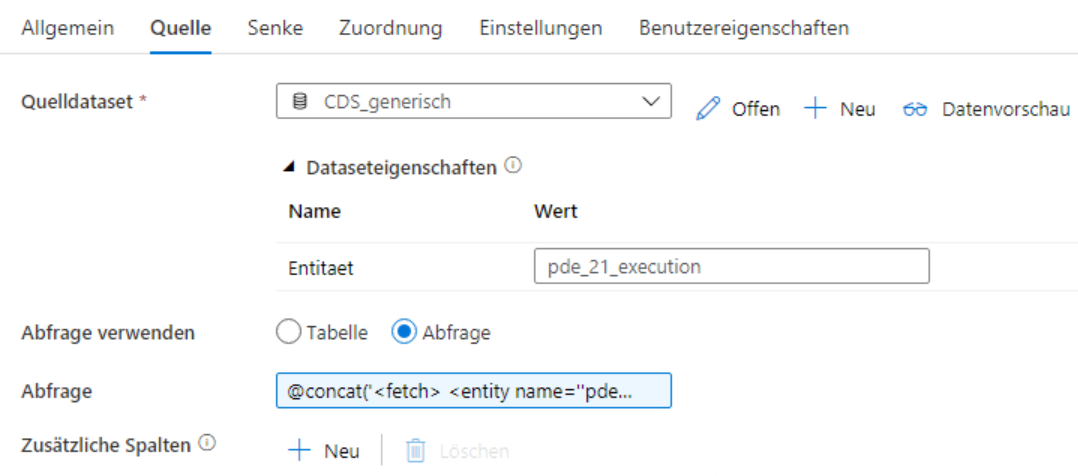
Wie man sieht, verwenden wir ein Fetch-XML als Abfrage mit
- einem Filter-Kriterium, da wir nur bestimmte Datensätze ermitteln wollen. (Deswegen ist die Abfrage auch dynamisch)
- genannten Attributnamen, da wir nicht alle Spalten übertragen wollen
- einem Join (link-entity) auf eine andere Entität, aus der wir auch einige Attribute entnehmen.
Die Senke sieht so aus:
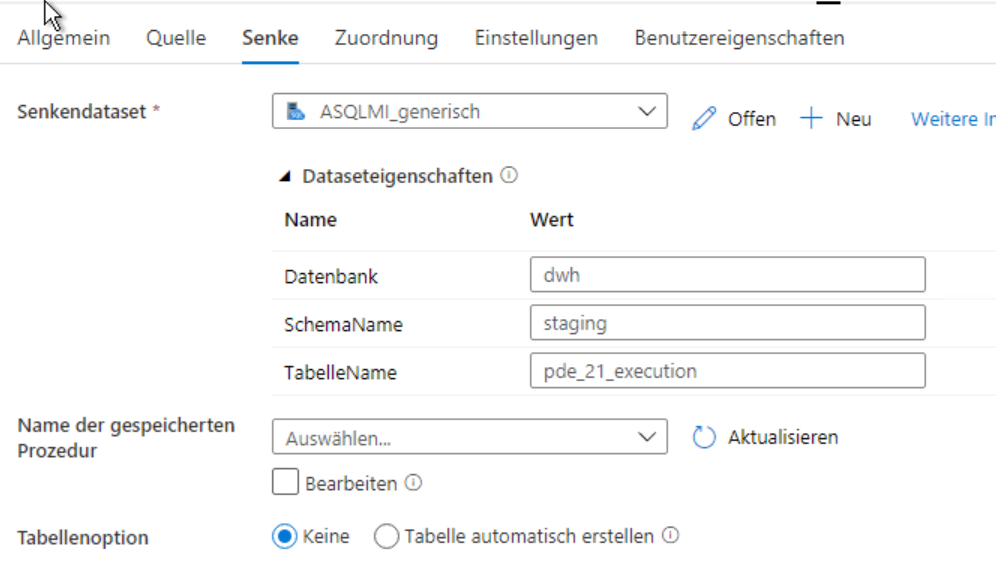
Hier ist eigentlich nur zu beachten, dass wir keine Tabellen-Option gewählt haben, also die Tabelle nicht automatisch gemäß des Schemas aus der Quelle erstellen lassen.
Der Zuordnungs-Reiter sieht wie folgt aus:

Also verwenden wir ein dynamisches Mapping.
Lösung
Die Lösung ist damit auch klar: Wir brauchen ein Schema in der Zuordnung. Es reicht aber nicht aus, das Schema zu importieren, weil beim Importieren des Schemas das gleiche passieren kann: Wenn eine Spalte NULL-Werte hat (im Sample) wird sie nicht als Quell-Spalte gesehen, z.B. hier (man sieht nur einen Ausschnitt):
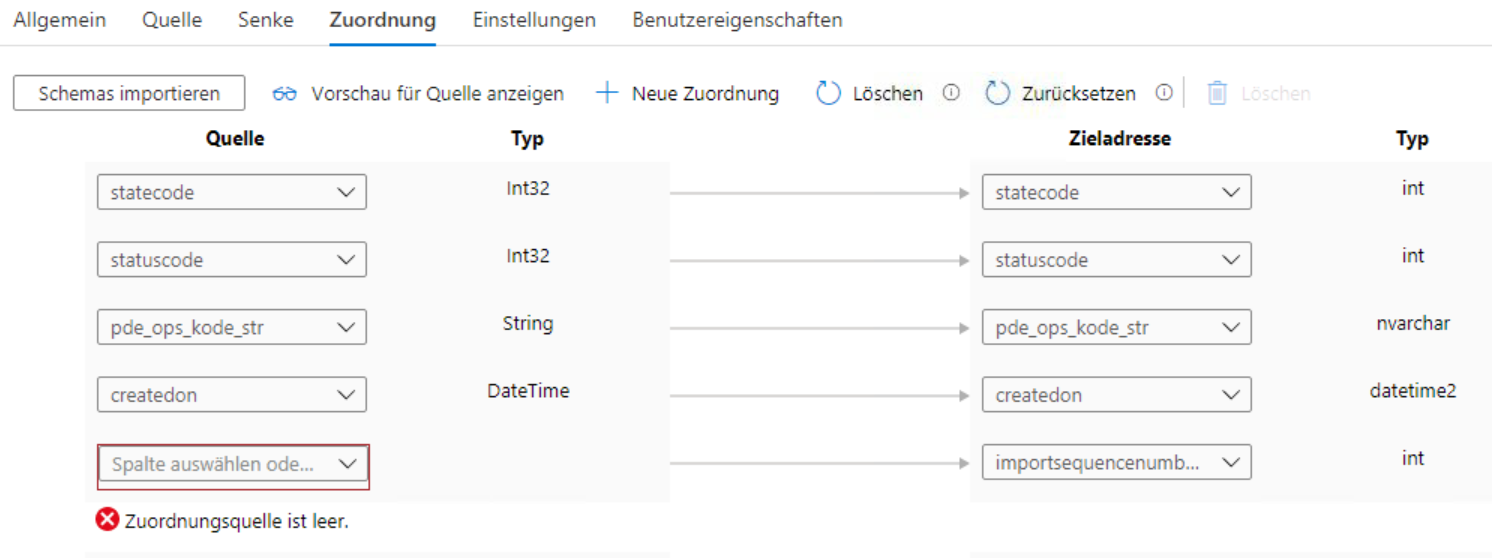
Wir müssen also ein dynamisches Schema in der Zuordnung angeben:

Wenn wir diese dynamische Zuordnung definiert haben, wobei wir für jede Spalte eine Definition hinterlegt haben, funktioniert es 🙂
Wie kommen wir nun zu der Lösung?
Vorgehen
Wir müssen also ein Mapping definieren, das so aussieht:
{
"type": "TabularTranslator",
"mappings": [
{
"source": {
"name": "statecode",
"type": "Int32"
},
"sink": {
"name": "statecode",
"type": "Int32"
}
},
{
"source": {
"name": "statuscode",
"type": "Int32"
},
"sink": {
"name": "statuscode",
"type": "Int32"
}
}
]
}
In diesem Beispiel werden zwei Spalten gemappt (statecode und statuscode) – und die Spalten heißen jeweils in der Quelle und im Ziel gleich.
Wie können wir nun ein solches JSON einfach erzeugen?
In unserem Falll war es so, dass wir alle Zieltabellen bereits angelegt hatten. Das kann man zum Beispiel dadurch erreichen, dass man als erstes die Tabelle als ganzes (also nicht mit Fetch-XML) kopiert – und in der Senke „Tabelle automatisch erstellen“ anwählt.
Dann sind wir so vorgegangen (was ich im Nachfolgenden genauer beschreiben werde):
- In der Zuordnung Schema importieren
- Im Code der Pipeline den entsprechenden Block (translator) kopieren
- In einem JSON-Editor fehlende Mappings (es steht nur eine Sink aber keine Source drin) korrigieren
- Zuordnung wieder löschen
- dynamischen Inhalt hinzufügen als @json(<generiertes JSON>)
Nun die Punkte im Detail:
1. In der Zuordnung Schema importieren
Das ist klar.
2. Im Code der Pipeline den entsprechenden Block (translator) kopieren
Über das Symbol {} gelangt man zur Codeansicht der Pipeline:

Diesen Code kopiert man in einen JSON-Editor (z.B. Visual Studio). Dort sucht man nach „TabularTranslator“. Man findet dann eine Stelle, die ungefähr so aussieht:
...
"translator": {
"type": "TabularTranslator",
"mappings": [
{
"source": {
"name": "statecode",
"type": "Int32"
},
"sink": {
"name": "statecode",
"type": "Int32"
}
},
{
"source": {...
(Falls man in seinem Code mehrere Copy-Tasks hat, muss man natürlich aufpassen. Allerdings ist vor dem translator-Knoten der sink-Knoten und danach der inputs- und outputs-Knoten, so dass man genau sieht, an welcher Stelle man gerade ist)
Wir entnehmen nun diesen Code – die geschweifte Klammer nach >>“translator“ : <<
3. In einem JSON-Editor fehlende Mappings (es steht nur eine Sink aber keine Source drin) korrigieren
Wenn wir diesen Code genauer anschauen, sehen wir die source-sink-Paare. Allerdings sind dort, wo der automatische Schema-Import keine Treffer finden konnte (weil die Spalten in der Quelle wegen der NULL-Werte nicht drin waren), keine source-Knoten vorhanden.
Aus
…
{
"sink": {
"name": "importsequencenumber",
"type": "Int32"
}
},
…
machen wir also folgendes:
...
{
"source": {
"name": "importsequencenumber",
"type": "Int32"
},
"sink": {
"name": "importsequencenumber",
"type": "Int32"
}
},
...
Wir verwenden also den gleichen Namen und den gleichen Datentyp.
4. Zuordnung wieder löschen
Dieser Schritt ist wieder einfach. Man muss auf den Papierkorb klicken.
5. dynamischen Inhalt hinzufügen als @json()
Der Link „Dynamischen Inhalt hinzufügen“ erscheint, wenn man mit der Maus in die Nähe kommt. Dort klickt man drauf und kann im Editor Code eingeben.
Der Code sieht dann z.B. so aus:
@json('{
"type": "TabularTranslator",
"mappings": [
{
"source": {
"name": "statecode",
"type": "Int32"
},
"sink": {
"name": "statecode",
"type": "Int32"
}
},
{ ...
Man beachte, dass ich nach @json( ein einfaches Anführungszeichen und innerhalb des JSON doppelte Anführungszeichen verwendate habe.
Eine Sache muss man hier noch beachten – es kann sein, dass der Code zu lang wird, so dass Azure Data Factory einen Fehler anzeigt. Wie man den behebt, beschreibe ich im nächsten Blogeintrag.