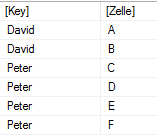
Das ist also die Lösung des Problems. Natürlich kann man noch die Value-Spalte löschen, z.B. mit SELECTCOLUMNS.
Wir haben uns hier folgendes zu nutze gemacht:
Wenn man als Trenner | verwendet, kann man die eingebauten Funktionen PATHITEM, PATHLENGTH verwenden
Wenn man einen anderen Trenner verwendet, kann man ggf. den Trenner durch | ersetzen
GENERATESERIES erzeugt eine einspaltige Tabelle (Spalte heißt Value) mit Zahlen von 1 bis n
Für Fortgeschrittene: Einen String in einer Tabelle splitten
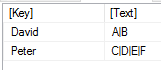
Im obigen Beispiel haben wir einen Text gesplittet. Nun kann es aber sein, dass man in einer Tabelle eine Spalte hat, die man splitten will und dann entsprechend mehr Zeilen bekommen will.
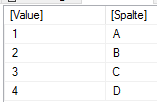
Zunächst erstelle ich die Ausgangstabelle wie oben. Dies steht dann in der Variable tabelle:
Ausgangstabelle
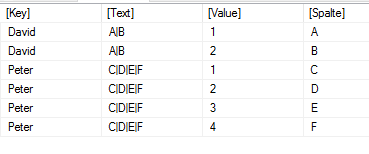
Das GENERATE führt dann für jede Zeile die GENERATESERIES – Funktion aus. Dort steht der jeweilige Text aus der Zeile. Die PATHLENGTH ist also für die erste Zeile 2, für die zweite 4. Das Ergebnis vom GENERATE ist somit:
Über das Addcolumns holen wir uns die jeweilige Stelle aus dem zu splittenden String:
In 2018 hatte ich schon mal was über DMVs (Data Management Views) geschrieben – damals noch über die aus der MOLAP-Welt. Es gibt sie natürlich auch für tabulare Modelle (s. Link oben).
Über die DMVs kann man sich z.B. ausgeben lassen,
wann Partitionen zuletzt verarbeitet wurden
in welchen Ordnern welche Kennzahlen liegen
welche Tabellen es gibt
mit welchen Formeln berechnete Spalten oder Measures berechnet werden
Dazu führt man die entsprechende DMV (Syntax s. obigen Link) einfach im SQL Server Management Studio in einer neuen Query aus. Die Query kann auch eine DAX-Query sein, auch wenn es natürlich kein DAX ist, was wir hier ausführen.
Ich hatte nun einmal die Aufgabenstellung alle Measures zu finden, die einen bestimmten String (z.B. einen Measurenamen) enthalten. Leider unterstützt die DMV-Sprache kein LIKE 🙁
Aber es wird die INSTR-Funktion unterstützt. Sucht man z.B. alle Measures, die „Mapping Fachabt“ enthalten, feuert man folgende Abfrage ab:
SELECT * FROM $System.TMSCHEMA_MEASURES
WHERE INSTR([Expression], 'Mapping Fachabt', 1)>1
Noch ein Hinweis: Wenn man nach einem einfachen Anführungszeichen sucht (was ja in der obigen Syntax als Indikator für eine Zeichenkette fungiert), muss man es verdoppeln. Wenn man nach „Filter(All(“ plus einem einfachen Anführungszeichen am Ende suchen will, kann man das mit folgender Abfrage machen:
SELECT * FROM $System.TMSCHEMA_MEASURES
WHERE INSTR([Expression], 'Filter(All(''', 1)>1
Wir hatten einen Cube (tabular model), das wir ausreichend getestet hatten. Wir hatten auch Filter (Slices in Power BI bzw. Filter in Excel Pivot) auf das Attribut Land getestet.
Als wir aber nun eine Rolle anlegten, die auf ein Land filterte, funktionierten unsere Berichte nicht mehr für diese Personen.
Da mich das sehr überrascht hat, möchte ich hier die Details beschreiben.
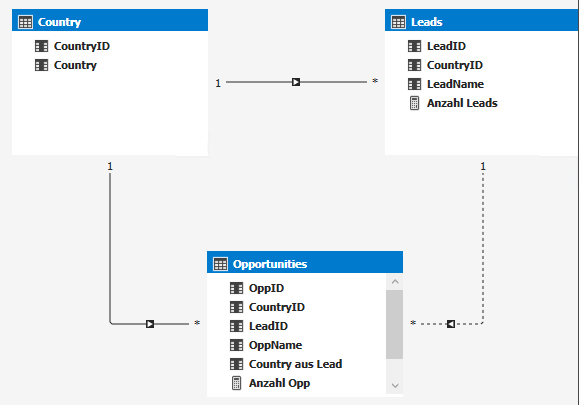
Beispiel-Cube
Wir erstellen einen Cube mit 3 Tabellen:
Country
Lead
Opportunity
Leads und Opportunities haben jeweils ein Land – und sind damit mit der Tabelle Country verbunden.
Opportunities können aus Leads hervorgehen. Dafür haben Opportunities eine LeadID, die aber leer sein kann. Außerdem kann das Land des Leads unterschiedlich vom Land der daraus generierten Opportunity sein.
Da diese Relationen einen Zirkel bedeuten würden, ist die Beziehung zwischen Lead und Opportunity auf inaktiv gesetzt – und kann dann über USERELATIONSHIP() in einem Measure verwendet werden.
Datenmodell mit aktiven und inaktiven Verbindungen
Als Measures definieren wir:
Anzahl Leads:=COUNTROWS(Leads)
Anzahl Opp:=COUNTROWS(Opportunities)
Anzahl Opportunities via Leads:=CALCULATE(COUNTROWS(Opportunities), USERELATIONSHIP(Leads[LeadID],Opportunities[LeadID]))
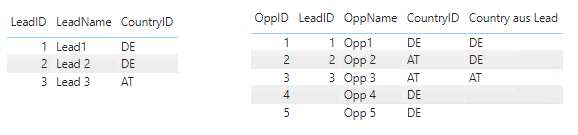
In den Tabellen haben wir folgende Beispieldaten:
Beispieldaten
Somit ergeben sich für die Measures folgende Ergebnisse:
Filter
Measure
Wert
IDs
ohne
Anzahl Leads
3
1,2,3
ohne
Anzahl Opp
5
1,2,3,4,5
ohne
Anz Opp via Lead
5
1,2,3,4,5
Deutschland
Anzahl Leads
2
1,2
Deutschland
Anzahl Opp
3
1,4,5
Deutschland
Anz Opp via Lead
2
1,2
Österreich
Anzahl Leads
1
3
Österreich
Anzahl Opp
2
2,3
Österreich
Anz Opp via Lead
1
3
Ergebnisse
Soweit ist das wenig überraschend.
Wenn wir jetzt aber eine Rolle mit Row Level Security – Filter =Country[Country]="Deutschland" definieren, so hätte ich erwartet, dass wir die Werte erhalten, die in obiger Tabelle unter Deutschland stehen.
Das stimmt auch für die beiden ersten Measures. Allerdings gibt das Measure „Anzahl Opportunities via Leads“ folgenden Fehler zurück:
Error: The UseRelationship() and CrossFilter() functions may not be used when querying ‚Opportunities‘ because it is constrained by row-level security defined on ‚Leads‘ or related tables.
Das finde ich sehr verblüffend. Eigentlich halte ich das für einen Bug. Da er aber so (mindestens) seit SSAS 2016 enthalten ist, gehe ich davon aus, dass Microsoft das nicht so sieht.
Deswegen sollte man mit USERELATIONSHIP() sehr sparsam umgehen, da sich dadurch Nebeneffekte auf Row Level Security ergeben.
(Nur als Randbemerkung: Bei meinem Kunden hatte ich eine andere Fehlermeldung (ambiguous paths). Ich weiß nicht, ob es am Patch-Level lag oder ich die Situation nicht 100% genau nachstellen konnte)
In der Regel lesen Cubes (tabulare Modelle) Daten aus einem DWH, also meist relationalen Datenbanken. Es kann aber sinnvoll sein, das Ergebnis eines Cubes als Quelle für einen anderen Cube zu verwenden. In einem Kundenprojekt benötigten wir das, weil die Preisberechnung in einem Cube implementiert war und in einem anderen Cube verwendet werden sollte.
Dann hat man also ein oder mehrere DAX-Statements, die man in den Cube laden will. Während die Verwendung eines DAX-Statements gradlinig funktioniert, ist es schwer, mehrere DAX-Statements (mit dem gleichen Cube als Quelle) zu verwenden.
Dieser Post zeigt, wie es funktioniert.
Problem
Nehmen wir für unser Beispiel an, dass wir zwei DAX-Abfragen von einem bestehenden Cube in einen neuen Cube importieren wollen. Um ein einfaches Beispiel zu haben, verwenden wir als Abfrage einfach:
evaluate {1}
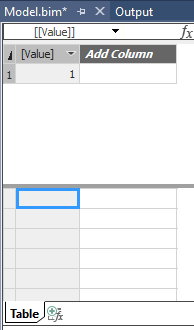
Dies liefert eine Tabelle mit einer Spalte („[Value]“) und einer Zeile, die den Wert 1 hat.
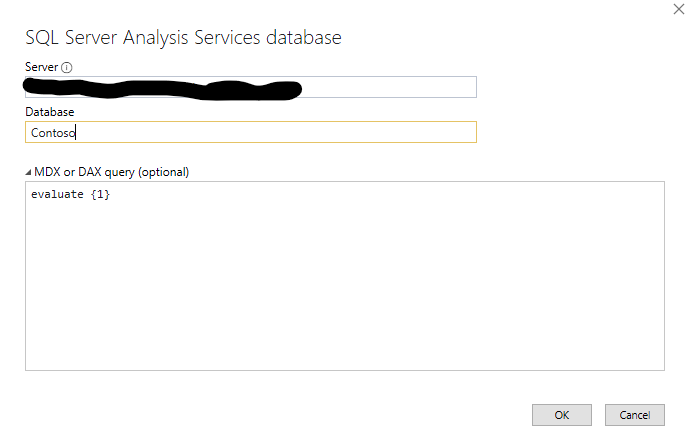
Um diese Abfrage in den neuen Cube zu laden, gehen wir ganz normal im Visual Studio vor – genauso wie man es in Power BI auch machen würde:
Wir definieren eine neue Datenquelle vom Typ „SQL Server Analysis Services-Datenbank“:
Eingabe eins DAX-Statements bei einer neu erstellten Datenquelle vom Typ SSAS
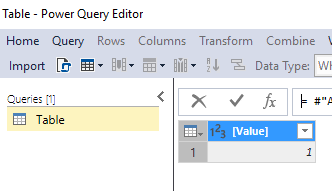
Um diese Daten als Tabelle im Cube zu haben, muss man auf der Datenquelle rechte Maustaste > „Import New Tables“anklicken. Das Power-Query-Fenster öffnet sich:
Power-Query-Editor für die DAX-Abfrage
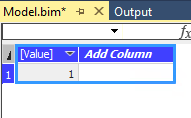
Über „Import“ wird diese Abfrage automatisch ausgeführt und man erhält eine neue Tabelle mit Namen „Table“, die nur eine Spalte „[Value]“ hat und dort eine Zeile mit 1:
Tabelle mit Ergebnis des DAX-Statements
Versucht man aber nun analog eine zweite Abfrage (mit evaluate {2}) auszuführen, scheint es zunächst zu funktionieren. Allerdings wird keine zweite Datenquelle angelegt, sondern die bestehende verändert, so dass bei einem Refresh die oben gezeigte Tabelle eine 2 statt einer 1 zeigt.
Es ist nicht möglich, zwei unterschiedliche DAX-Abfragen auf dieselbe Quelle abzufeuern
Man muss es also anders probieren.
Lösungsidee
Bei meinem Blogeintrag zur Datumsdimension in SSAS hatte ich bereits die M-Syntax Value.NativeQuery verwendet. Dies werden wir hier mit der Datenquelle SSAS verwenden.
Dazu gehen wir wie folgt vor:
Zunächst löschen wir die Datenquelle mit dem DAX-Statement und erstellen eine neue, allerdings ohne Eingabe eines DAX-Statements.
Quelle vom Typ SSAS
Im zweiten Fenster geben wir nur die Connection an:
Verbindung zu einer SSAS Datenbank – ohne DAX-Statement
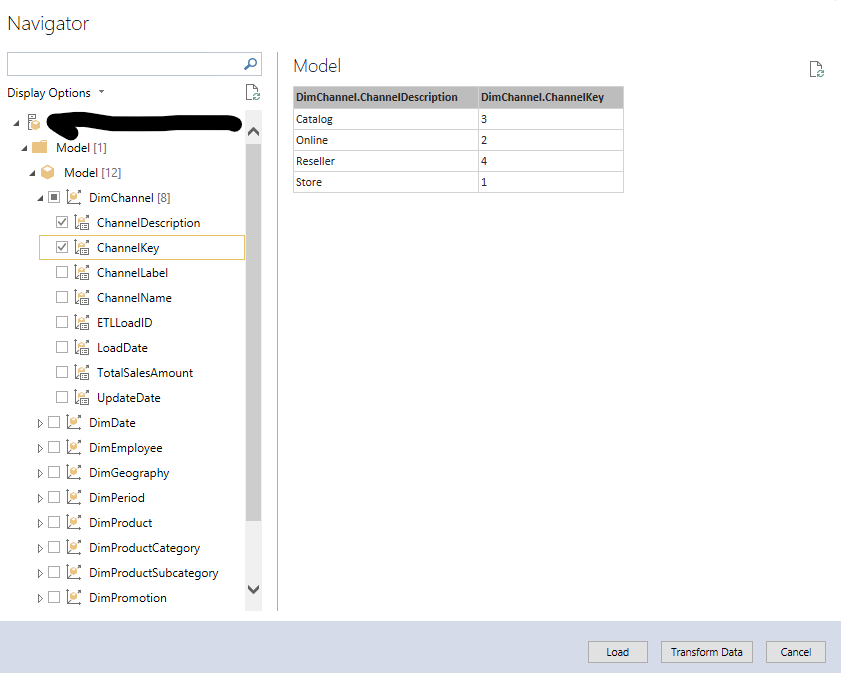
Um auszuprobieren, ob sie funktioniert, gehen wir mit der rechten Maustaste auf diese Verbindung und klicken auf „Import new tables“:
Auswahl einer kleinen (!) Tabelle
Wir sollten darauf achten, dass wir eine kleine Tabelle auswählen. Dann klicken wir auf „Load“.
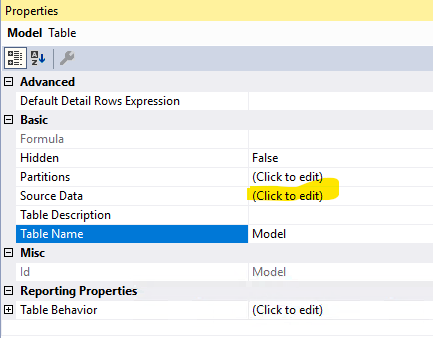
Damit wird eine neue Tabelle namens „Model“ mit dieser Struktur angelegt. Das M hinter der Abfrage finden wir in den Eigenschaften bei Source Data:
Eigenschaften der neuen Tabelle –> Source Data, um M zu sehen
Das M-Statement sieht so aus:
let
Source = #"Name der Datenquelle",
Model1 = Source{[Id="Model"]}[Data],
Model2 = Model1{[Id="Model"]}[Data],
#"Added Items" = Cube.Transform(Model2,
{
{Cube.AddAndExpandDimensionColumn, "[DimChannel]", {"[DimChannel].[ChannelDescription].[ChannelDescription]", "[DimChannel].[ChannelKey].[ChannelKey]"}, {"DimChannel.ChannelDescription", "DimChannel.ChannelKey"}}
})
in
#"Added Items"
Wenn wir das Statement nun so abändern, haben wir die Problemstellung gelöst:
let
Source = #"Name der Datenquelle",
Tabelle = Value.NativeQuery(Source, "evaluate {1}")
in
Tabelle
Nach dem Löschen der alten zwei Spalten und einem Refresh, sieht das Ergebnis wie gewünscht aus:
Ergebnis der DAX-Abfrage als Tabelle
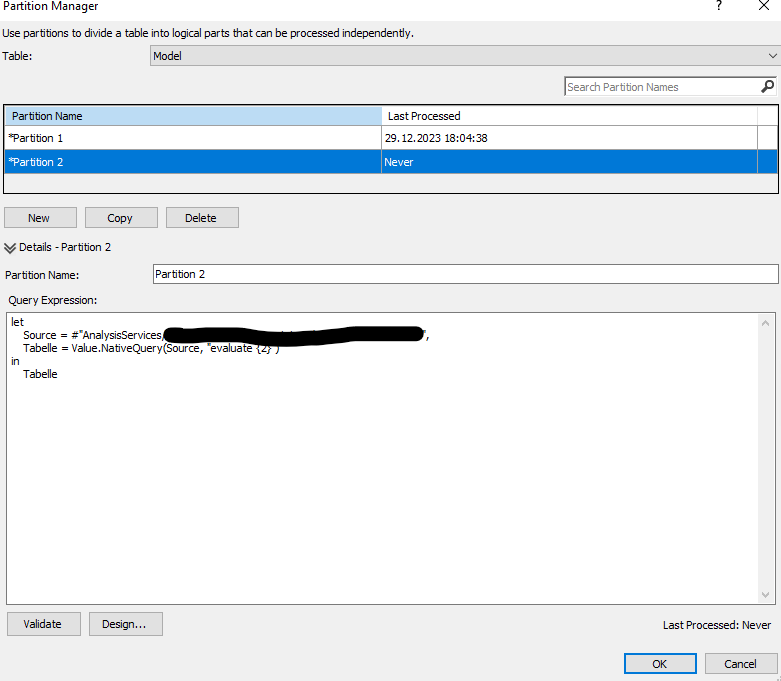
Um nun zu zeigen, dass die zweite Abfrage auch funktioniert, erstellen wir einfach eine zweite Partition mit der gleichen M-Abfrage, wobei wir nur 1 durch 2 ersetzen:
2 Partitionen
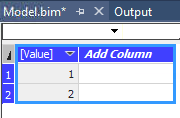
Nach einem Refresh auf die Tabelle haben wir das Ergebnis:
fertig: Beide DAX-Statements wurden ausgeführt
Damit sind wir fertig!
Ich habe absichtlich das Beispiel der Partitionen verwendet, da dies ein klassisches Anwendungsszenario ist, bei dem mehrere Abfragen auf die gleiche Quelle abgefeuert werden müssen.
Optimierungen
Der Nachteil an dieser Implementierung ist, dass das DAX-Statement immer komplett geschrieben werden muss.
Wenn man sich aber nun vorstellt, dass es ein kompliziertes DAX-Statement ist, das sich je Partition nur um eine Zahl unterscheidet (in unserem Beispiel eine Zahl von 0 bis 99), dann möchte man das DAX-Statement nicht 100x schreiben – weil das natürlich sehr schlecht zu warten ist.
Deswegen sehen bei uns die M-Befehle so aus:
let
Source = #"Name der Datenquelle",
P = Value.NativeQuery(
Source, Text.Combine({Vorne, "1", Hinten}, "")
)
in
P
Wir sehen, dass wir zwei Variablen (Vorne und Hinten) verwenden. In der gezeigten Partition wird dann die Zahl 1 zwischen Vorne und Hinten eingetragen.
In unserem Beispiel aus dem Blog wäre
Vorne = "evaluate {"
und
Hinten = "}"
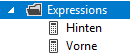
Jetzt ist nur noch die Frage, wo wir diese Variablen hinterlegen können. Das sind die Expressions:
Expressions
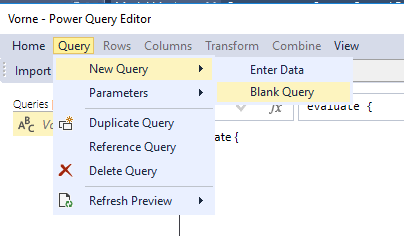
Um diese zu erstellen, klicken wir mit der rechten Maustaste auf „Expressions“ und dann auf „Edit Expressions“:
Dann legen wir eine leere Query an:
eine leere Quelle im Power Query Editor anlegen
Die Query können wir umbenennen über die Name-Property. Den Wert der Variablen tippen wir oben einfach ein:
Beispiel der Variable „Vorne“
In unserem echten Anwendungsfall haben wir den Text (hier evaluate { ) nicht einfach eingetragen, sondern mit = zugewiesen, also = "evaluate {" geschrieben. Dann muss man Anführungszeichen, die in dem DAX-Statement vorkommen, verdoppeln, da der Interpreter sonst denkt, der String wäre zu Ende.
Seit über einem Jahr gibt es nun die Möglichkeit, Cubes, die man – wie bisher auch – in Visual Studio erstellt, nun direkt nach Power BI in einen Arbeitsbereich zu deployen.
Dies hat einige Vorteile:
Man muss keine eigenen Analysis Services Dienste mehr vorhalten (weder on prem noch Azure Analysis Services)
Das spart ggf. Lizenzen, Server-Kapazitäten und verringert die Komplexität einer Lösung
Man kann dennoch auf die Datasets von außerhalb zugreifen (z.B. Excel Pivot, Reporting Services – generell mit jedem Tool, das Zugriffe auf Cubes unterstützt)
Als wir zum ersten Mal ein solches Cube-Deployment allerdings durchgeführt haben, ging das nicht, ohne über die ein oder andere Klippe zu stolpern. Deshalb beschreibe ich hier, wie man vorgehen muss.
Voraussetzungen
Ausgangssituation: Ich gehe davon aus, dass wir im Visual Studio einen Cube erstellt haben.
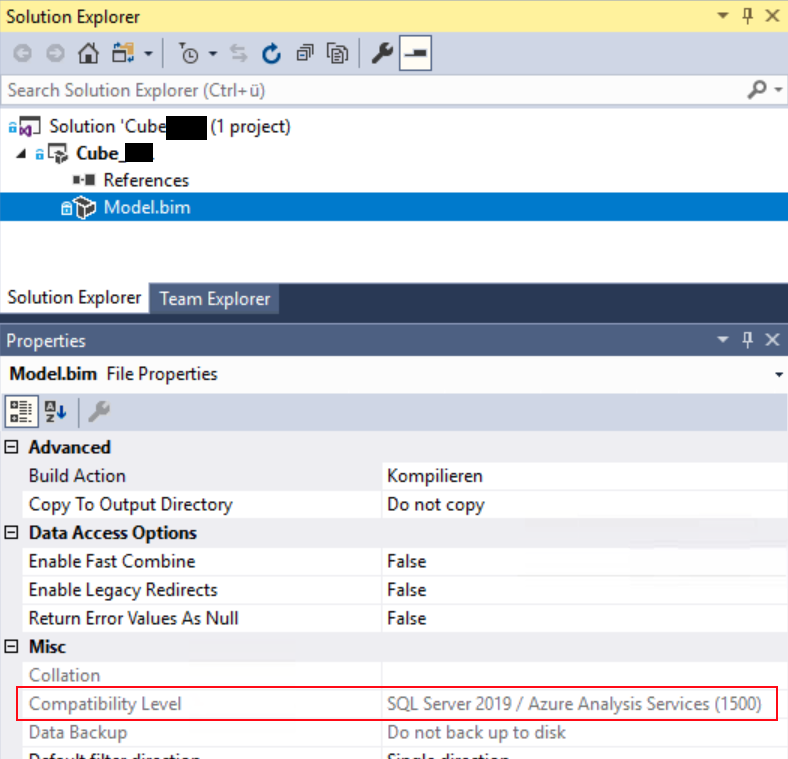
Wichtig ist, dass wir den Kompatibilitätsmodus auf 1500 gesetzt haben:
Kompatibilitätsmodus auf 1500 gesetzt
(Man beachte, dass diese Einstellung nur bearbeitet werden kann, wenn das Model.bim im Visual Studio geöffnet ist)
Build und Deployment
Über einen Build erzeugen wie dann ein asdatabase-File:
Build eines Cube-Projekts innerhalb Visual Studio
Das erzeugt im bin-Folder folgende Dateien (das ist noch alles unabhängig von unserem Deployment nach Power BI Premium):
Ordner mit den daraus resultierenden Dateien
In der Regel machen wir es nun so, dass wir in unser Quell-Code-Verwaltungssystem das „Model.asdatabase“ einchecken und von einem Branch in den nächsten (-> Test -> Prod) bewegen – die anderen Dateien werden für den Deployment Wizard nicht benötigt. Hier werden wir gleich einen Fallstrick sehen – aber dazu gleich mehr.
Nun wollen wir das so erzeugte Model.asdatabase-File in einen Power BI Premium-Arbeitsbereich deployen. Dazu benötigen wir als erstes die Adresse, auf die wir es deployen können. Diese finden wir im Arbeitsbereich.
Es ist zu beachten, dass das ein Premium-Feature ist. Der Arbeitsbereich muss deshalb entweder einer Power-BI-Premium-Kapazität zugeordnet sein (erkennbar am Symbol ) oder unter einer Power BI Premium Einzelbenutzerlizenz laufen (erkennbar am Symbol ). Unter Einstellungen findet man dann im Reiter Premium die Adresse für die Verbindung:
Einstellungen des Power BI Premium Arbeitsbereichs
Mit der Arbeitsbereichverbindung kann man sich dann auch im SQL Server Management Studio auf den XMLA-Endpoint verbinden. Das werden wir später noch brauchen.
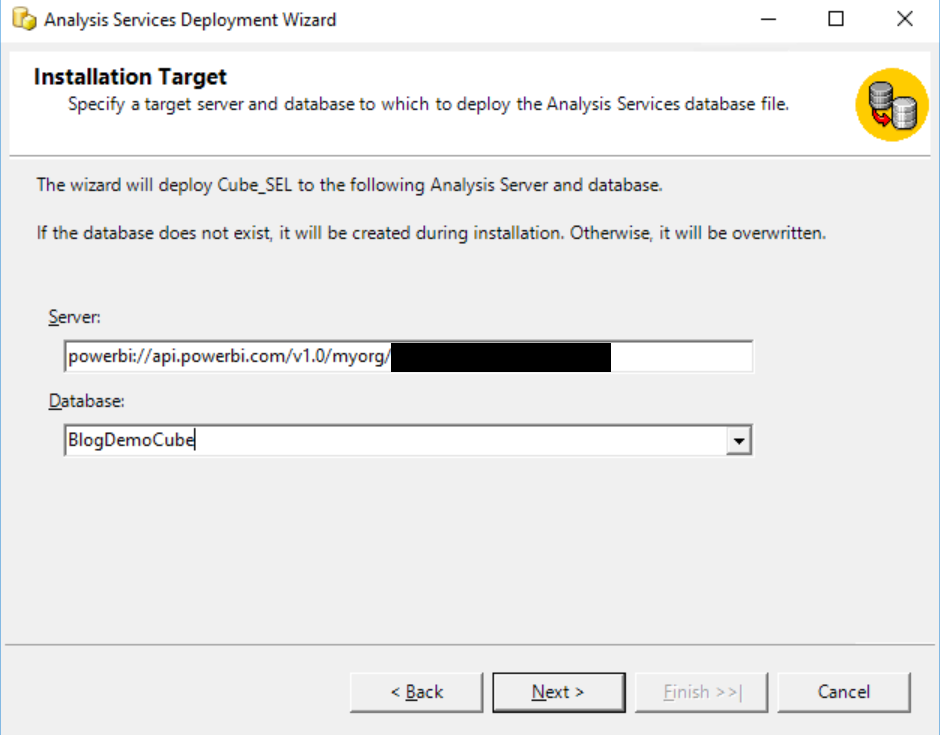
Nun können wir versuchen, den Cube zu deployen. Dazu starten wir den Analysis Services Deployment Wizard und wählen die Model.asdatabase-Datei aus. Als Server tragen wir die powerbi://-Adresse von oben ein:
Eingabe des Servers und Datasetnamen im Analysis Services Deployment Wizard
Die Eintragungen auf den nächsten Seiten sind nicht relevant, zumal wir ja den Cube zum ersten Mal deployen. In der Regel deploye ich sonst Rollen nicht und übernehme die bisher geltenden Einstellungen. Auf das Default Procesisng verzichten wir jetzt (wir machen das nachher vom SQL Server Management Studio aus).
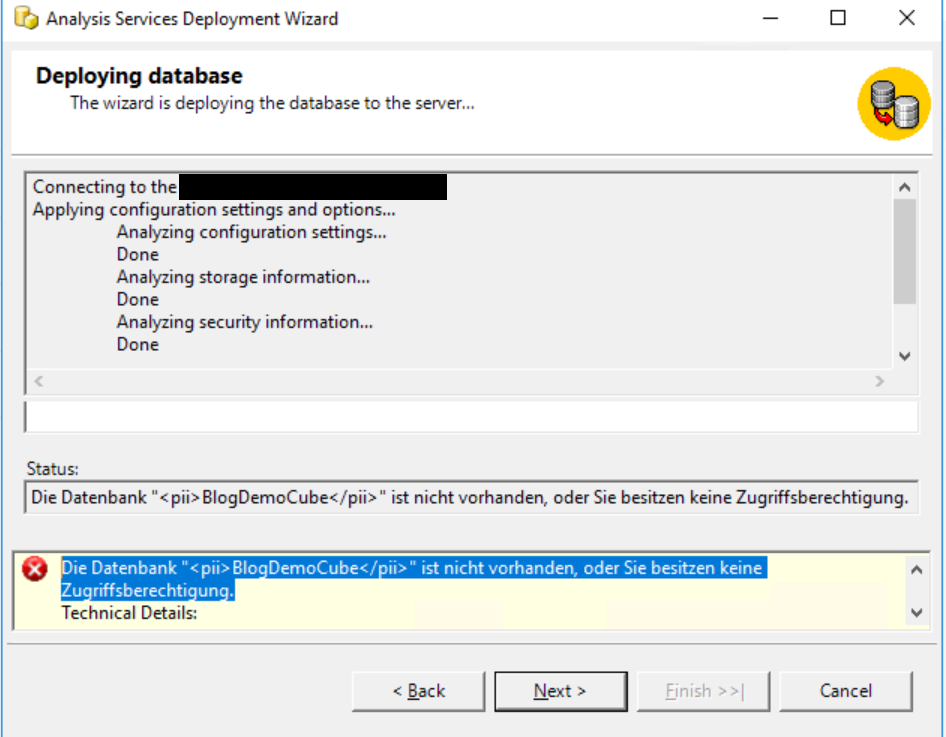
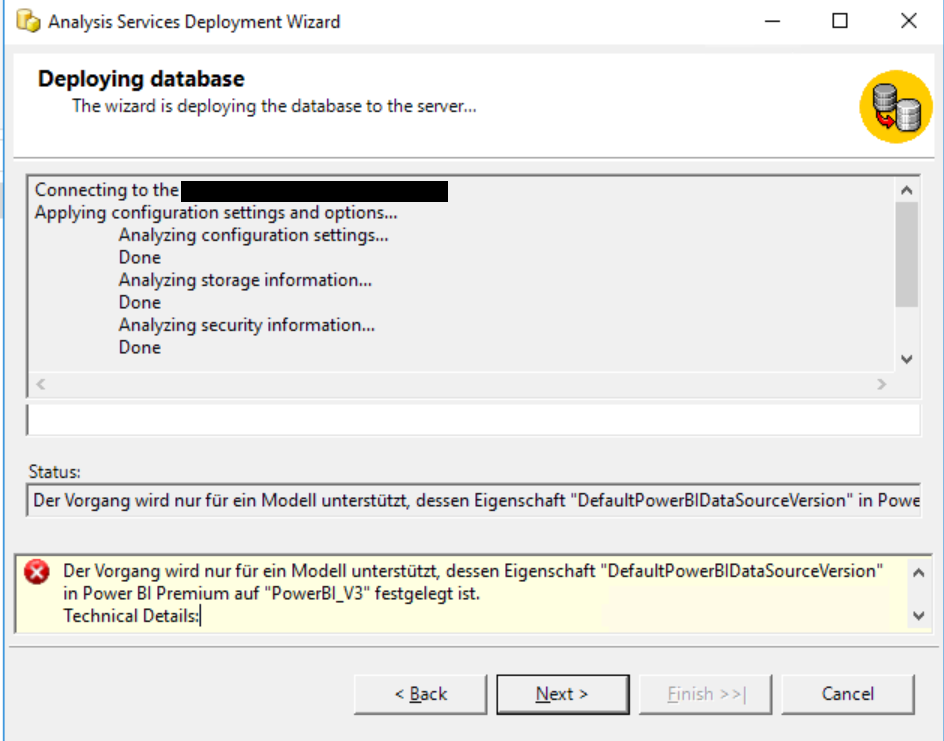
Witzigerweise erhalten wir die Fehlermeldung „Die Datenbank „BlogDemoCube“ ist nicht vorhanden, oder Sie besitzen keine Zugriffsberechtigung.“ Das ist richtig – aber wir wollen den Cube ja auch erstmalig deployen. Hier der Screen Shot:
Erste Fehlermeldung beim Deployment
Die Lösung für dieses Problem ist, die Datei „Model.deploymentoptions“, die wir vorher gesehen haben, auch in das Verzeichnis zu legen, von wo aus wir die Datei „Model.asdatabase“ deployen. Wenn wir das aus dem bin-Verzeichnis direkt machen, wäre uns das ganze also gar nicht passiert, da Visual Studio diese Datei dort ja ablegt. Wie gesagt, verwenden wir aber unterschiedliche Branches für unsere Umgebungen und haben dort nur das Model.asdatabase eingecheckt und bisher (onprem Analysis Services oder Azure Analysis Services) konnten wir auch nur mit dem Model.asdatabase deployen. Die Datei „Model.deploymentoptions“ enthält darüber hinaus auch keine Informationen, die nicht im Wizard abgefragt werden. Das macht das ganze umso komischer.
Die „Model.deploymentoptions“-Datei sieht so aus (es ist also tatsächlich keine wertvolle Information, sondern kann einfach so übernommen werden):
Durchläuft man nun nochmal den Deployment-Prozess, ändert sich die Fehlermeldung zu „Der Vorgang wird nur für ein Modell unterstützt, dessen Eigenschaft „DefaultPowerBIDataSourceVersion“ in Power BI Premium auf „PowerBI_V3″ festgelegt ist.“:
Diese Fehlermeldung ist immerhin aussagekräftig. Wir lösen das Problem, indem wir die datei Model.asdatabase in einem Editor (sagen wir Notepad++) bearbeiten. Wir fügen nach „culture“ die geforderte Eigenschaft ein: „defaultPowerBIDataSourceVersion“: „powerBI_V3“,
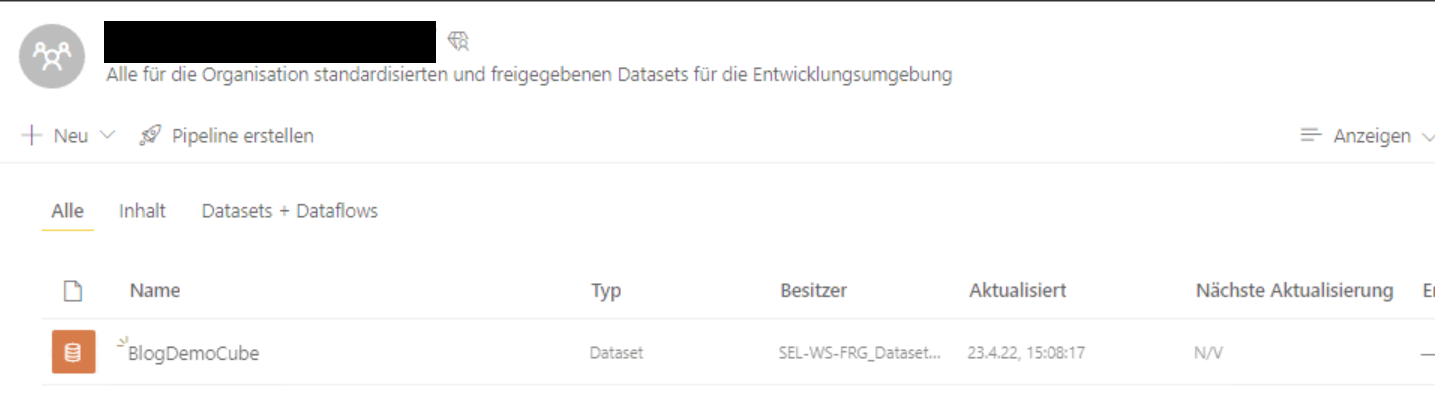
Cube als Power BI Premium Dataset – sichtbar im Arbeitsbereich
Außerdem sieht man ihn im SQL Server Management Studio:
sichtbar im SQL Server Management Studio
Allerdings sind wir noch nicht fertig, da wir den Cube noch verarbeiten müssen.
Davor möchte ich aber noch ein paar Hinweise geben:
Beide „Hacks“ (Model.deploymentoptions und defaultPowerBIDataSourceVersion) sind nur für das erste Deployment relevant. Deployt man eine neue Version des Cubes über ein bestehendes Power BI Premium Dataset, sind beide Veränderungen nicht mehr notwendig.
Man könnte defaultPowerBIDataSourceVersion auch im Model.bim eintragen. Allerdings ist das nicht ratsam, da dann das Model.bim nicht mehr in einem Arbeitsbereichserver geöffnet werden kann und man somit nicht mehr im Visual Studio daran weiterarbeiten kann.
Cube verarbeiten
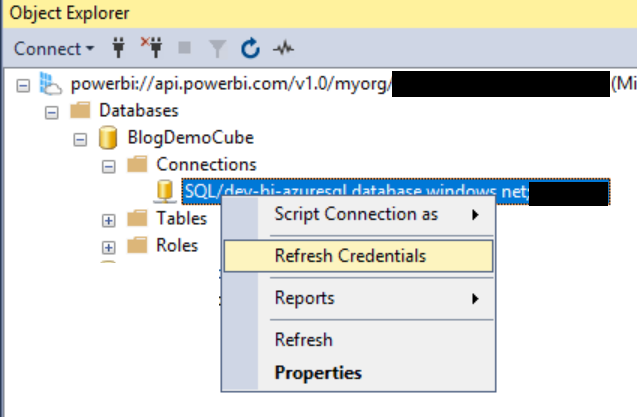
Machen wir also weiter: Wie nach jedem Deployment (auch nach Azure Analysis Services) muss man die Credentials neu eintragen, die für die Verbindung auf die zugrundeliegende Datenbank benutzt werden:
Credentials eintragen
(In unserem Fall verwenden wir SQL Server Authentifizierung auf einen SQL Server in Azure)
Nun könnten wir – wenn es ein Azure Analysis Services-Cube wäre, die Cubeverarbeitung erfolgreich durchführen. Wenn wir aber nun die Verarbeitung starten, kommt eine Fehlermeldung:
Start der Cubeverarbeitung
Die Fehlermeldung lautet: „Failed to save modifications to the server. Error returned: ‚{„error“:{„code“:“DMTS_DatasourceHasNoCredentialError„,“pbi.error“:{„code“:“DMTS_DatasourceHasNoCredentialError“,“details“:[{„code“:“Server“,“detail“:{„type“:1,“value“:“//servername//“}},{„code“:“Database“,“detail“:{„type“:1,“value“:“//datenbankname//“}},{„code“:“ConnectionType“,“detail“:{„type“:0,“value“:“Sql“}}],“exceptionCulprit“:1}}}“. Das ist überraschend, da wir ja die Credentials gesetzt haben. Wir müssen aber noch in der Power BI App im Arbeitsbereich Einstellungen des Datsets machen:
Einstellungen des Datasets aufrufen
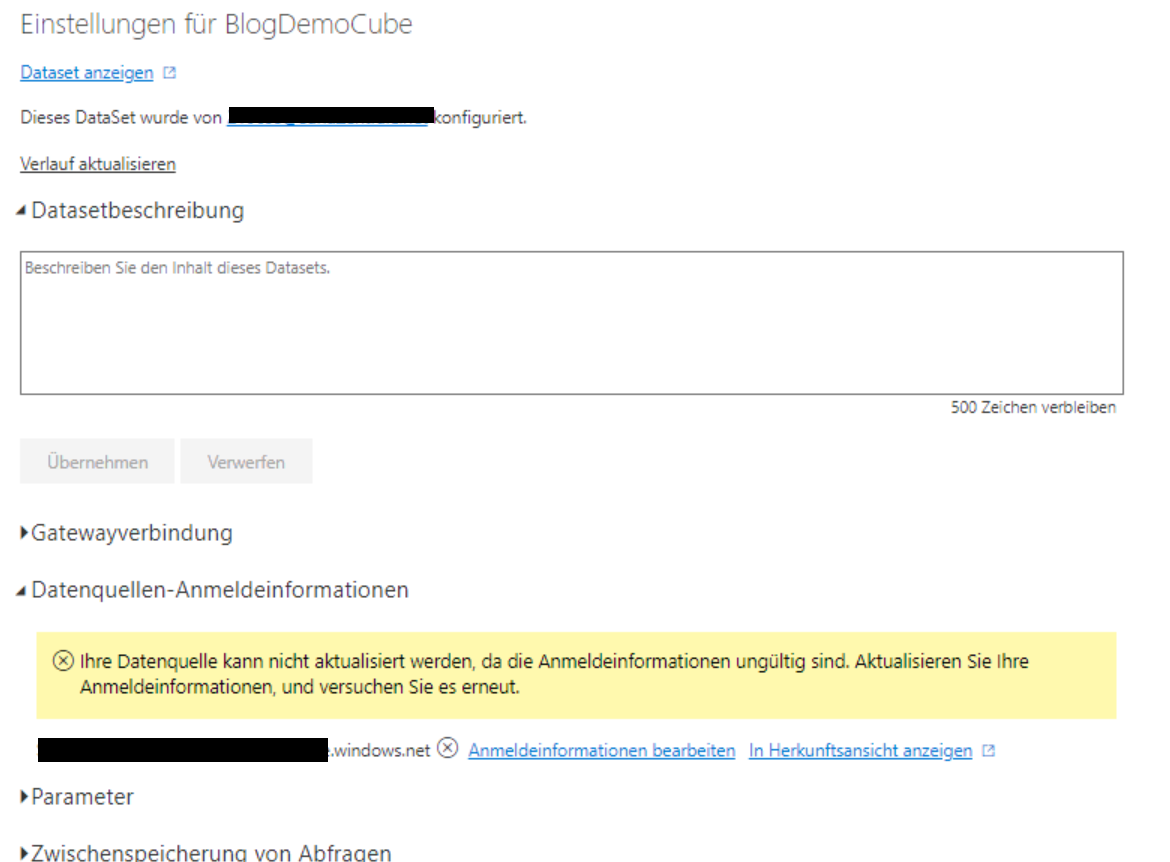
Hier sehen wir schon unter „Datenquellen-Anmeldeinformationen“ den Fehler: „Ihre Datenquelle kann nicht aktualisiert werden, da die Anmeldeinformationen ungültig sind. Aktualisieren Sie Ihre Anmeldeinformationen, und versuchen Sie es erneut.“
Fehler unter Datenquellen-Anmeldeinformationen
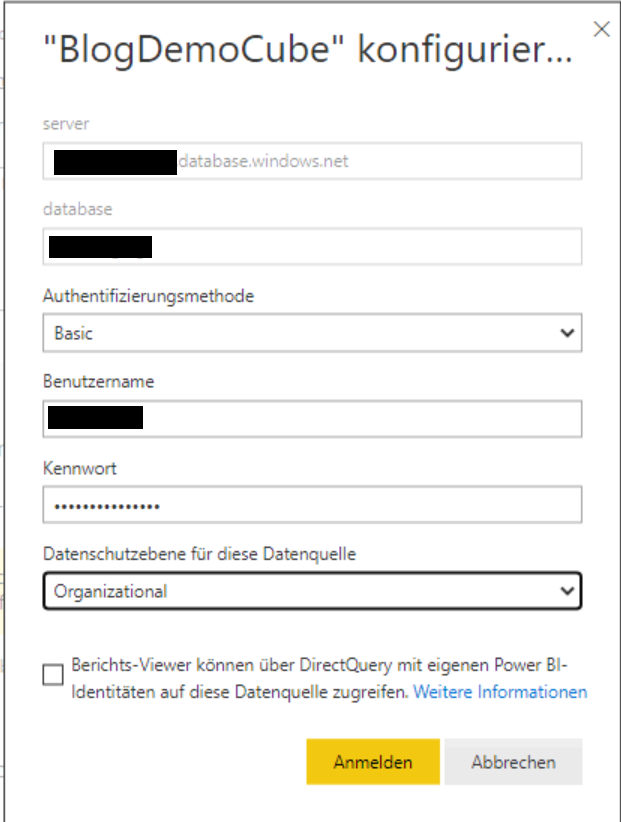
Die Lösung ist nun nahe liegend: Unter „Anmeldeinformationen bearbeiten“ muss man die gleichen Credentials nochmal eintragen:
Credentials nochmal eintragen
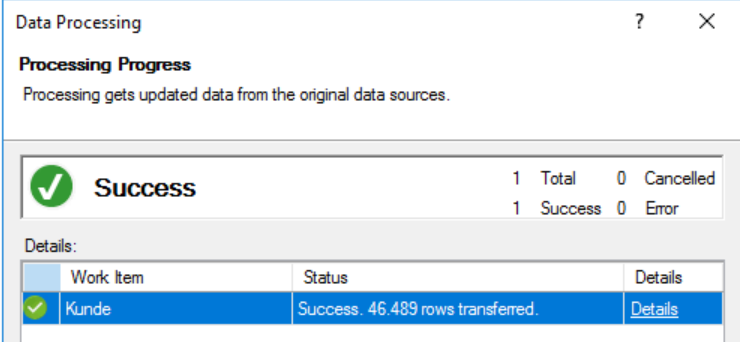
Mit diesen Einstellungen funktioniert jetzt die Cubeverarbeitung:
erfolgreiche Cubeverarbeitung
Damit haben wir die Aufgabe komplett erledigt.
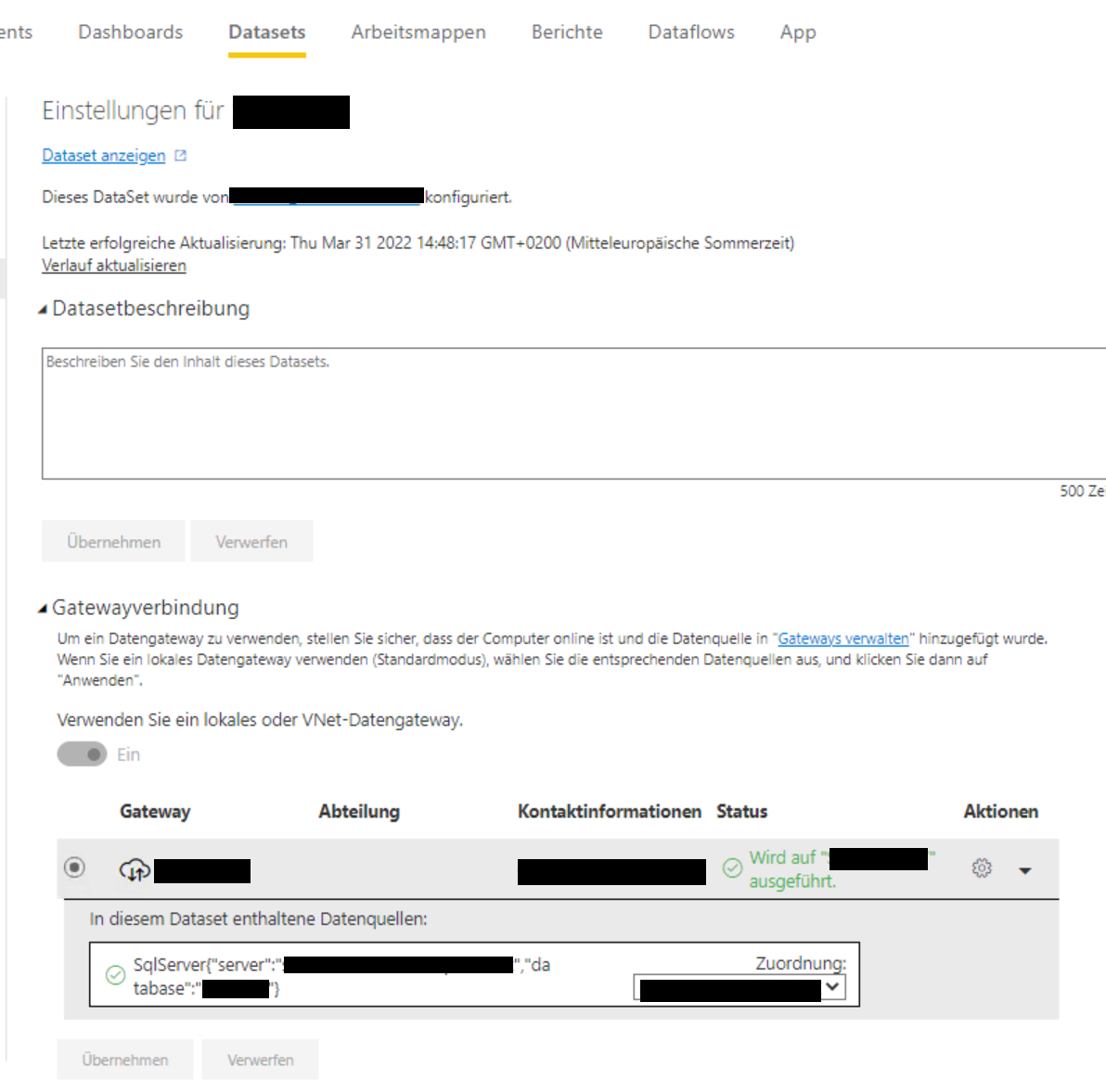
Eine Anmerkung gibt es allerdings noch: Ich habe den Fall mit einer Datenquelle in Azure durchgespielt. Wenn die Datenquelle on premise liegt, ändert sich die letzte Aktion (Einstellungen des Datasets) leicht: In diesem Fall müssen dort die Gatewayeinstellungen korrekt gesetzt werden:
Einstellungen der Gatewayverbindung eines Datasets
Damit man diese Einstellung machen kann, muss der eigene User als Mitglied auf dem gateway eingetragen sein (über Power BI > Einstellungen > Gateways verwalten).
In einem aktuellen Projekt hatten wir die Aufgabe, in mehreren Cubes insgesamt ca. 250 Rollen anzulegen bzw. zu aktualisieren. Ausgangspunkt war eine interne Umstrukturierung der Vertriebsstruktur, was dann in Rollen abgebildet werden musste.
[Nebenbemerkung: Natürlich gibt es andere Optionen wie z.B. dynamische Rechtevergabe mittels USERNAME() oder CUSTOMDATA(). In diesem Projekt war aber eine hart kodierte Lösung sinnvoll, da die Rechtevergabe nicht dynamisch erfolgen soll und die Benutzer eh zu AD-Gruppen zugeordnet sind.]
Somit war die Anforderung, ca. 250 Sätze mit folgenden Informationen automatisch zu Rollen umzusetzen:
Name des Cubes
Name der Rolle
Beschreibung
Filtereinstellungen für bestimmte Kunden-Attribute (Hub, Market, Sales Country) und ggf. Element-Attribute
Zuordnung einer oder mehrerer AD-Gruppen zu dieser Rolle
Deswegen haben wir zunächst eine Tabelle angelegt, in der wir diese Metadaten speichern konnten:
Tabelle mit den Metdadaten (Auszug)
Das CREATE-Statement sieht so aus:
CREATE TABLE [Config].[CubeRollen](
[Cube] [nvarchar](100) NOT NULL,
[CubeRolle] [nvarchar](50) NOT NULL,
[Description] [nvarchar](1000) NULL,
[Filter_SalesCountry] [nvarchar](3) NULL,
[Filter_HubId] [int] NULL,
[Filter_RegionId] [int] NULL,
[Filter_ElementNo] [int] NULL,
[Bemerkung] [nvarchar](1000) NULL,
[ADGruppe] [nvarchar](100) NULL,
[AdminRights] [tinyint] NOT NULL,
[ProcessPermission] [tinyint] NOT NULL,
[ProcessAndReadPermission] [tinyint] NOT NULL,
CONSTRAINT [PK_Config_CubeRollen] PRIMARY KEY CLUSTERED
(
[Cube] ASC,
[CubeRolle] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, OPTIMIZE_FOR_SEQUENTIAL_KEY = OFF) ON [PRIMARY]
) ON [PRIMARY]
GO
ALTER TABLE [Config].[CubeRollen] ADD DEFAULT ((0)) FOR [AdminRights]
GO
ALTER TABLE [Config].[CubeRollen] ADD DEFAULT ((0)) FOR [ProcessPermission]
GO
ALTER TABLE [Config].[CubeRollen] ADD DEFAULT ((0)) FOR [ProcessAndReadPermission]
GO
Jetzt betrachten wir mal, wie wir die Rollen automatisch anlegen wollen. Dazu gibt es JSON-Befehler (früher XMLA), die der Analysis Services (ab SQL 2016) ausführt. Für die 4.Zeile des obigen Screen Shots sieht der Befehl so aus: (wenn man die Syntax nicht kennt, kann man sich so einen Befehl über die Skript-Funktionalität im SQL Server Management Studio erstellen lassen)
Damit wir diese JSONs erstellen können, brauchen wir noch eine Konfigurationstabelle, in der wir definieren, wie sich die Einträge in den einzelnen [Filter_…]-Spalten in diese Bedingungen übersetzen. Diese Übersetzung kann für jeden Cube unterschiedlich sein. Dazu haben wir folgende Tabelle angelegt:
CREATE TABLE [Config].[CubeFilterDefinition](
[Cube] [nvarchar](100) NOT NULL,
[Filter_SalesCountry] [nvarchar](100) NULL,
[Filter_HubId] [nvarchar](100) NULL,
[Filter_RegionId] [nvarchar](100) NULL,
[Filter_ElementNo] [nvarchar](100) NULL,
CONSTRAINT [PK_Config_CubeFilterDefinition] PRIMARY KEY CLUSTERED
(
[Cube] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO
INSERT INTO [Config].[CubeFilterDefinition]
SELECT 'AFD Order Entry Reporting',
'Customer[Sales country Id]=\"##Wert##\"',
'Customer[Hub ID]=\"##Wert##\"',
'Customer[Region ID]=##Wert##',
NULL
INSERT INTO [Config].[CubeFilterDefinition]
SELECT 'DCH Sales Margin Analysis',
'Customer[Sales country Id]=\"##Wert##\"',
'Customer[Hub ID]=\"##Wert##\"',
'Customer[RegionID]=##Wert##',
'Element[Element No]=\"##Wert##\"'
Man sieht, dass die Einschränkung aufs Element-Attribut nur beim 2. Cube möglich ist (weil der erste Cube gar nicht diese Dimension hat).
Für eine Verallgemeinerung muss man natürlich die Filter_…-Spalten an die jeweilige Situation anpassen.
Nun bauen wir das SQL-Statement für die Erstellung des JSON schrittweise zusammen. Für jeden Schritt verwende ich eine eigene CommonTableExpression, damit man die Schritte einfach einzeln bauen kann.
with piv as
(
select r.[Cube], r.CubeRolle,
r.Filter_SalesCountry as FilterWert, f.Filter_SalesCountry as FilterCondition from config.CubeRollen r
inner join config.CubeFilterDefinition f
on r.Cube=f.Cube
UNION
select r.[Cube], r.CubeRolle,
convert(nvarchar(10), r.Filter_HubId) as FilterWert, f.Filter_HubID as FilterCondition from config.CubeRollen r
inner join config.CubeFilterDefinition f
on r.Cube=f.Cube
UNION
select r.[Cube], r.CubeRolle,
convert(nvarchar(10), r.Filter_RegionId) as FilterWert, f.Filter_RegionID as FilterCondition from config.CubeRollen r
inner join config.CubeFilterDefinition f
on r.Cube=f.Cube
UNION
select r.[Cube], r.CubeRolle,
convert(nvarchar(10), r.Filter_ElementNo) as FilterWert, f.Filter_ElementNo as FilterCondition from config.CubeRollen r
inner join config.CubeFilterDefinition f
on r.Cube=f.Cube
)
select * from piv
Dieses SQL liefert die Spalten:
Cube
CubeRolle
FilterWert: der jeweilige Wert, auf den gefiltert werden soll (also in unserem Andorra-Beispiel von oben: 20 bzw. AD
FilterCondition: die jeweilige Definition aus der Meta-Tabelle, wie dieser Filterwert anzuwenden ist (z.B. Customer[Hub ID]=\“##Wert##\“ bzw. Customer[Sales country Id]=\“##Wert##\“)
Im nächsten Schritt ermitteln wir aus der FilterCondition die Tabelle (im Beispiel Customer). Das geht mit der SQL-Funktion charindex zum Suchen des Texts „[„:
,
pivMitFilteredTable as (
select *, left(FilterCondition, charindex('[', FilterCondition, 1)-1) as FilteredTable from piv
)
select * from pivMitFilteredTable
Im nächsten Schritt gruppieren wir nach FilteredTable und bauen die Bedingung pro Tabelle zusammen (in unserem Beispiel Customer[Hub ID]=\“20\“ && Customer[Sales country Id]=\“AD\“):
,
RollenFilter as (
select [Cube], CubeRolle, FilteredTable , string_agg(convert(nvarchar(max), replace(FilterCondition, '##Wert##', FilterWert)), ' && ') as Filter from pivMitFilteredTable
group by [Cube], CubeRolle, FilteredTable
)
select * from RollenFilter
Nun ergänzen wir diese Tabelle um die Description, die ADGruppe und die modelPermission (hier werden Admin- und processor-Rechte separat vergeben):
,
FDef as (
select rf.*, r.Description, ADGruppe,
case when AdminRights=1 then N'administrator'
when ProcessPermission=1 then N'refresh'
when ProcessAndReadPermission=1 then N'readRefresh'
else N'read' end as modelPermission from RollenFilter rf
left join Config.CubeRollen r
on rf.[cube] = r.[Cube] and rf.CubeRolle = r.CubeRolle
)
select * from FDef
Jetzt haben wir alles, um die ersten JSON-Fragmente zusammenzubauen.
Außerdem ist es erlaubt, in der Definition in dem Feld ADGruppe mehrere AD-Gruppen zu spezifizieren – indem sie durch , getrennt sind. Zusätzlich wird die Domäne vor die AD-Gruppe geschrieben. Somit entsteht aus
,f2 as (
select [cube], CubeRolle, Rumpf_Anfang, Rumpf_ende, '{
"name": "' + FilteredTable + '",
"filterExpression": "' + Filter + '"
}' as FilterZeile, FilteredTable, Filter from ff
)
select * from f2
Dann müssen wir nur noch mit einem Group By Cube + CubeRolle das JSON pro Rolle bauen und konkatenieren:
,
erg as (
select [cube], CubeRolle, Rumpf_Anfang +
isnull(
', "tablePermissions": [' +
string_agg(convert(nvarchar(max), FilterZeile), ', ')
+ ']', '')
+ Rumpf_ende xmla from f2
group by [cube], CubeRolle, Rumpf_Anfang , Rumpf_ende
)
select '{
"sequence":
{
"operations": [
' + string_agg(xmla, ',')
+ ']}}'
from erg
Somit siehr das fertige SQL so aus:
with piv as
(
select r.[Cube], r.CubeRolle,
r.Filter_SalesCountry as FilterWert, f.Filter_SalesCountry as FilterCondition from config.CubeRollen r
inner join config.CubeFilterDefinition f
on r.Cube=f.Cube
UNION
select r.[Cube], r.CubeRolle,
convert(nvarchar(10), r.Filter_HubId) as FilterWert, f.Filter_HubID as FilterCondition from config.CubeRollen r
inner join config.CubeFilterDefinition f
on r.Cube=f.Cube
UNION
select r.[Cube], r.CubeRolle,
convert(nvarchar(10), r.Filter_RegionId) as FilterWert, f.Filter_RegionID as FilterCondition from config.CubeRollen r
inner join config.CubeFilterDefinition f
on r.Cube=f.Cube
UNION
select r.[Cube], r.CubeRolle,
convert(nvarchar(10), r.Filter_ElementNo) as FilterWert, f.Filter_ElementNo as FilterCondition from config.CubeRollen r
inner join config.CubeFilterDefinition f
on r.Cube=f.Cube
),
pivMitFilteredTable as (
select *, left(FilterCondition, charindex('[', FilterCondition, 1)-1) as FilteredTable from piv
),
RollenFilter as (
select [Cube], CubeRolle, FilteredTable , string_agg(convert(nvarchar(max), replace(FilterCondition, '##Wert##', FilterWert)), ' && ') as Filter from pivMitFilteredTable
group by [Cube], CubeRolle, FilteredTable
)
,
FDef as (
select rf.*, r.Description, ADGruppe,
case when AdminRights=1 then N'administrator'
when ProcessPermission=1 then N'refresh'
when ProcessAndReadPermission=1 then N'readRefresh'
else N'read' end as modelPermission from RollenFilter rf
left join Config.CubeRollen r
on rf.[cube] = r.[Cube] and rf.CubeRolle = r.CubeRolle
)
, ff as (
select [cube], CubeRolle,
'{
"createOrReplace": {
"object": {
"database": "' + [Cube] + '",
"role": "' + CubeRolle + '"
},
"role": {
"name": "' + CubeRolle + '",
"description": "' + isnull(Description, '') + '",
"modelPermission": "' + modelPermission + '", ' + isnull('
"members": ['
+ (select string_agg('{
"memberName": "' + replace(case when value like '%\%' then value else 'DOMÄNE\'+ value end, '\', '\\') + '"
}', ',') from ( Select value from string_split(ADGruppe, ',')) as x) + '
]', '') as Rumpf_Anfang, '
}
}
}' as Rumpf_ende, FilteredTable, Filter, description, modelPermission, ADGruppe
from FDef
)
,f2 as (
select [cube], CubeRolle, Rumpf_Anfang, Rumpf_ende, '{
"name": "' + FilteredTable + '",
"filterExpression": "' + Filter + '"
}' as FilterZeile, FilteredTable, Filter from ff
)
,
erg as (
select [cube], CubeRolle, Rumpf_Anfang +
isnull(
', "tablePermissions": [' +
string_agg(convert(nvarchar(max), FilterZeile), ', ')
+ ']', '')
+ Rumpf_ende xmla from f2
group by [cube], CubeRolle, Rumpf_Anfang , Rumpf_ende
)
select '{
"sequence":
{
"operations": [
' + string_agg(xmla, ',')
+ ']}}'
from erg
Anpassungen
Theoretisch könnte man dieses JSON auch automatisch an den Analysis Services schicken (z.B. via ETL). In unserem Projekt haben wir es einfach mit Copy&Paste in das SQL Server Management Studio kopiert und dort ausgeführt.
Für jeden Anwendungsfall muss man natürlich die unterschiedlichen gefilterten Felder spezifizieren. Das bedeutet – wie oben angedeutet – die Anpassung der Datenbank-Struktur. Natürlich könnte man das Datenmodell auch so wählen, dass für unterschiedliche Filter keine Strukturänderung erforderlich wäre. Wir haben uns aber bewusst für die gezeigte Lösung entschieden, weil dadurch die Tabelle auch für Nicht-IT-ler verständlich bleibt und so die Meta-Daten von den Fachbereichen gepflegt werden können.
In meinen Projekten kommt es natürlich oft vor, dass man Datumsdimensionen benötigt.
Dazu verwende ich Stored Functions im SQL Server, um die Datumswerte mit allen gewünschten Attributen (wie Wochentag, Monat, Kalenderwoche, etc.) an den Analysis Services-Dienst weiter zu geben. Ich will das hier beschreiben, weil seit SSAS 2017 der Aufruf von Stored Functions gar nicht mehr so offensichtlich ist (wenn man die depracted Data Sources nicht verwenden will).
Das Vorgehen ist wie folgt:
Ermittle die Datumswerte, die die Datumsdimension enthalten soll. In der Regel ist das entweder ein Zeitraum oder distinkte Werte (z.B. bei einer Dimension, in der der Datenstand ausgewählt werden kann)
Liefere zu den ermittelten Datumswerten alle Attribute wie Wochentag, Monat, Kalenderwoche, etc.)
Gib diese Daten an den SSAS weiter
Wir benutzen hier bewusst einen getrennten Ansatz, erst die anzeigenden Datumswerte zu ermitteln und dann dazu die Attribute zu erzeugen. Dadurch erreichen wir die höchst mögliche Flexibilität. Man könnte zum Beispiel folgendes machen:
Wir nehmen alle Datumswerte vom Minimum der auftretenden Werte bis zum Maximum
Da aber Fehleingaben enthalten sind, und wir nicht alle Datumswerte vom 1.1.2000 bis 1.1.3000 in unserer Dimension haben wollen, nehmen wir nur die Datumswerte vom Minimum bis zum Ende nächsten Jahres und alle weiteren DISTINCTen Werte, die vorkommen.
Wir gehen so vor:
Als erstes legen wir einen Type an, der eine Liste von Datumswerten halten kann:
CREATE TYPE [dbo].[typ_Datumswerte] AS TABLE(
[datum] [date] NOT NULL,
PRIMARY KEY CLUSTERED
(
[datum] ASC
)WITH (IGNORE_DUP_KEY = OFF)
)
GO
In eine Variable dieses Datentyps können wir nun beliebige Datumswerte speichern. Wenn man zum Beispiel eine distinkte Menge an Datumswerten aus einer Faktentabelle speichern will, kann man das so machen:
DECLARE @d AS typ_Datumswerte
INSERT INTO @d SELECT DISTINCT Datum FROM Fakt_Auftragsbestand
Meistens benötigt man aber einen ganzen Zeitraum an allen möglichen Datumswerten. Dafür habe ich eine triviale Stored Function geschrieben:
-- =============================================
-- Author: Martin Cremer
-- Create date: 07.07.2015
-- Description: liefert alle Tage eines bestimmten Zeitraums
-- =============================================
CREATE FUNCTION [dbo].[f_alle_Datumswerte]
(
@von date,
@bis date
)
RETURNS
@tab TABLE
(
datum date
)
AS
BEGIN
while @von <= @bis
begin
insert into @tab select @von
set @von = dateadd(d, 1, @von)
end
RETURN
END
GO
Um einen ganzen Zeitraum nun in eine Variable des oben definierten Typs zu schreiben, geht man so vor:
DECLARE @d AS typ_Datumswerte
INSERT INTO @d
SELECT * FROM dbo.f_alle_Datumswerte(
(SELECT min(Datum) FROM Fakt_Auftragsbestand),
(SELECT max(Datum) FROM Fakt_Auftragsbestand)
)
Damit hätten wir den ersten Punkt erledigt. Kommen wir nun dazu, alle benötigten Attribute zu ermitteln. Dafür gibt es ein paar Hilfsfunktionen, deren 1. Version ich sogar am 1.1.2009 hier schon im Blog veröffentlicht hatte, und eine Funktion, die alles zusammenfasst. Zunächst die Hilfsfunktionen (auf die heutige Zeit angepasst, in der der SQL Server nativ die deutsche ISO-Woche ermitteln kann):
-- =============================================
-- Author: Martin Cremer
-- Create date: 16.8.2006
-- Description: ermittelt aus dem Datum den Wochentag (unabhängig von SET DATEFIRST): 1=Montag - 7=Sonntag
-- =============================================
CREATE FUNCTION [dbo].[getWochentag]
(
@dat date
)
RETURNS int
AS
BEGIN
DECLARE @Result int
SELECT @Result = (datepart(dw, @dat) - 1 + @@datefirst -1) % 7 +1
RETURN @Result
END
GO
CREATE FUNCTION [dbo].[getKW_Jahr](@h as date)
returns int
as
begin
return case
when datepart(isowk, @h)>50 and month(@h) = 1 then year(@h)-1
when datepart(isowk, @h)=1 and month(@h) = 12 then year(@h)+1
else year(@h)
end
end
GO
CREATE FUNCTION [dbo].[getKW_Woche](@h as date)
returns int
as
begin
return datepart(isowk, @h)
end
GO
Die geradlinige zusammenfassende Funtkion sieht dann so aus:
-- =============================================
-- Author: Martin Cremer
-- Create date: 07.07.2015
-- Description: liefert zu den übergebenen Datumswerten alle Attribute
-- =============================================
CREATE FUNCTION [dbo].[f_Datumsattribute]
(
@datumswerte as dbo.typ_Datumswerte readonly
)
RETURNS
@Ergebnis TABLE
(
Datum date NOT NULL,
[KW_ID] INT NOT NULL,
[KW_Jahr] SMALLINT NOT NULL,
[KW] NVARCHAR(10) NOT NULL,
[KW_Nr] SMALLINT NOT NULL,
[Monat_ID] INT NOT NULL,
[Monat_OhneJahr_ID] TINYINT NOT NULL,
[Monat] NVARCHAR(8) NOT NULL,
[Monat_OhneJahr] NVARCHAR(3) NOT NULL,
[Jahr] SMALLINT NOT NULL,
[Quartal_ID] SMALLINT NOT NULL,
[Quartal_OhneJahr_ID] TINYINT NOT NULL,
[Quartal_OhneJahr] NVARCHAR(50) NOT NULL,
[Quartal] NVARCHAR(50) NOT NULL,
[Wochentag_ID] int NOT NULL,
[Wochentag] nvarchar(20) NOT NULL,
[Wochentag_Kürzel] nvarchar(2) NOT NULL
)
AS
BEGIN
INSERT INTO @Ergebnis
(Datum, [KW_ID], [KW_Jahr], [KW], [KW_Nr], [Monat_ID], [Monat_OhneJahr_ID], [Monat], [Monat_OhneJahr], [Jahr],
[Quartal_ID], [Quartal_OhneJahr_ID], [Quartal_OhneJahr], [Quartal], [Wochentag_ID], [Wochentag], [Wochentag_Kürzel])
SELECT
x.datum,
x.KW_Jahr * 100 + x.KW /* 201501 für KW 01/2015*/,
x.KW_Jahr /*2015*/,
'KW ' + RIGHT('0' + CONVERT(NVARCHAR(2), x.KW), 2) + '/' + CONVERT(NVARCHAR(4), x.KW_Jahr) /* KW 01/2015*/,
x.KW /*1*/,
x.jahr * 100 + x.Monat /* 201501 für Jan 2015 */,
x.monat /* 1 */,
monate.monatsname + ' ' + CONVERT(NVARCHAR(4), x.jahr) /* Jan 2015 */,
monate.monatsname /* Jan */,
x.jahr,
x.jahr * 10 + x.quartal /* 20151 für Q1 2015 */,
x.quartal /* 1 */,
'Q' + CONVERT(NVARCHAR(1), x.quartal) /* Q1 */,
'Q' + CONVERT(NVARCHAR(1), x.quartal) + ' ' + CONVERT(NVARCHAR(4), x.jahr),
x.wochentagID,
Wochentage.Wochentagname,
Wochentage.Wochentagkurz
FROM
(SELECT [dbo].[getKW_Jahr](d.datum) AS KW_Jahr, [dbo].[getKW_Woche](d.datum) AS KW,
MONTH(d.datum) AS monat,
datepart(QUARTER, d.datum) AS quartal,
year(d.datum) AS jahr,
[dbo].[getWochentag](d.datum) as wochentagID,
d.datum
FROM @datumswerte as d) AS x
LEFT JOIN
(SELECT 1 AS monat, 'Jan' AS Monatsname UNION ALL
SELECT 2, 'Feb' UNION ALL
SELECT 3, 'Mär' UNION ALL
SELECT 4, 'Apr' UNION ALL
SELECT 5, 'Mai' UNION ALL
SELECT 6, 'Jun' UNION ALL
SELECT 7, 'Jul' UNION ALL
SELECT 8, 'Aug' UNION ALL
SELECT 9, 'Sep' UNION ALL
SELECT 10, 'Okt' UNION ALL
SELECT 11, 'Nov' UNION ALL
SELECT 12, 'Dez' ) AS monate
ON x.monat = monate.monat
LEFT JOIN
(SELECT 1 as WochentagID, 'Montag' Wochentagname, 'Mo' Wochentagkurz UNION ALL
SELECT 2, 'Dienstag', 'Di' UNION ALL
SELECT 3, 'Mittwoch', 'Mi' UNION ALL
SELECT 4, 'Donnerstag', 'Do' UNION ALL
SELECT 5, 'Freitag', 'Fr' UNION ALL
SELECT 6, 'Samstag', 'Sa' UNION ALL
SELECT 7, 'Sonntag', 'So' ) as Wochentage
ON x.wochentagID = Wochentage.WochentagID
RETURN
END
GO
Somit kann man nun obige Ermittlung der gewünschten Datumswerte um die Ausgabe der Attribute erweitern, also zum Beispiel so:
declare @tage as [dbo].[typ_Datumswerte]
INSERT INTO @tage select * from dbo.f_alle_Datumswerte(convert(date, '1.1.2020', 104), convert(date, '31.12.' + convert(nvarchar(4), year(getdate())), 104))
select * from dbo.f_Datumsattribute(@tage)
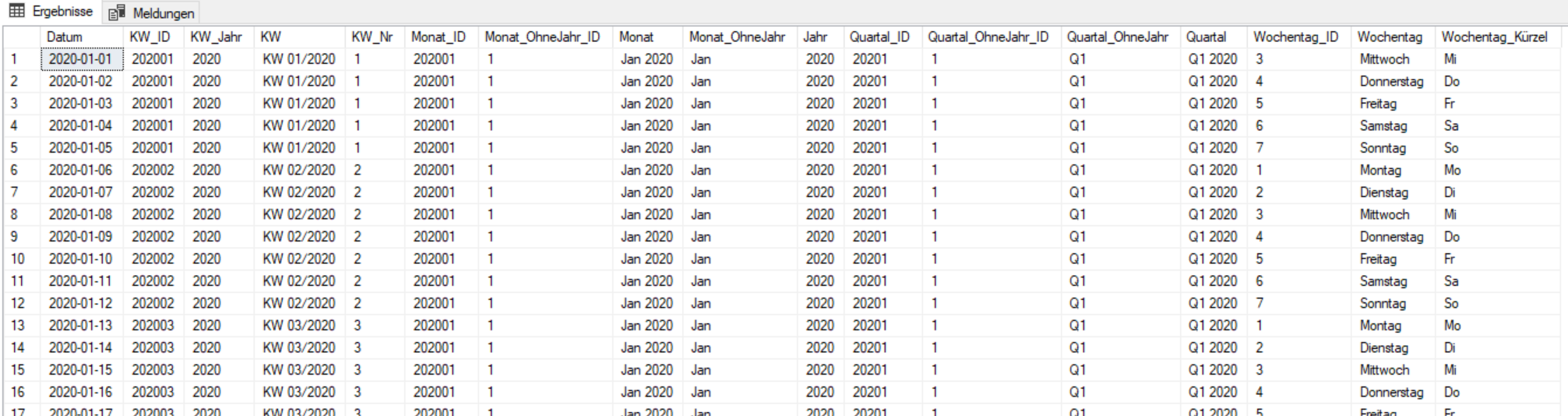
Das Ergebnis sieht dann so aus:
Ergebnis Datumswerte
Nun müssen wir dieses SQL nur noch im SSAS ausführen lassen. Seit viele Neuerungen aus PowerBI in das Produkt SSAS einfließen, hat sich auch die Art und Weise geändert, wie man das Ergebnis von SQL-Statements im SSAS einbinden kann. Früher war es ja ganz einfach ein SQL-Statement anstelle einer Tabelle (bzw. View) zu verwenden, heute muss man wie folgt vorgehen [Die Idee dazu fand ich in Chris Webbs sehr gutem BI-Blog (hier).]:
Wenn man in Visual Studio eine neue Tabelle hinzufügt, wird im Hintergrund M-Code erzeugt, der in etwa so aussieht:
let
Source = #"SQL/<host>;<Datenbank>",
meineTabelle = Source{[Schema="dbo",Item="Beispiel"]}[Data]
in
meineTabelle
Über die Properties der Tabelle > Quelldaten > (Zum Bearbeiten klicken) kann man diesen Code einsehen.
Zu verstehen ist der Code ja ganz leicht: Über Source wird die SQL-Connection auf dem Host <host> und Datenbank <Datenbank> geöffnet. Daraus wird im obigen Beispiel die Tabelle dbo.Beispiel geladen.
Wenn wir nun obiges SQL ausführen wollen, fügen wir zunächst auf den normalen Weg im UI eine neue Tabelle hinzu (welche ist vollkommen egal). Danach bearbeiten wir dieses M-Statement zu
let
Source = #"SQL/<Host>;<Datenbank>",
Entlassungsdatum = Value.NativeQuery(
Source,
"declare @tage as [dbo].[typ_Datumswerte]
INSERT INTO @tage select * from dbo.f_alle_Datumswerte(convert(date, '1.1.2020', 104), convert(date, '31.12.' + convert(nvarchar(4), year(getdate())), 104))
select * from dbo.f_Datumsattribute(@tage)"
)
in
Entlassungsdatum
Entscheidend ist also die Änderung von Source{}[Data] zu Value.NativeQuery().
Nun stellt sich aber die Frage, wie man bei einer Migration von einer früheren SSAS-Version auf SSAS 2016 die dortigen Display Folder überträgt, da sie leider bei einer „normalen“ Migration via Visual Studio verloren gehen, da Visual Studio die BIDS-Helper-spezifischen Einstellungen (BIDS Helper speichert diese Informationen als Annotations in einem eigenen Format) nicht kennt.
Bei der Suche nach einer Antwort fand ich die Seite http://www.kapacity.dk/migrating-ssas-tabular-models-to-sql-server-2016-translations-and-display-folders/.
Dort wird – kurz zusammengefasst – vorgeschlagen, das neue Objekt-Modell zu verwenden, um die Display Folder zu schreiben. Das (jetzt in SSAS 2016 sehr einfache) Objekt-Modell habe ich bereits in meinem letzten Blog-Eintrag beschrieben. Der Artikel schlägt vor, die Annotations vom BIDS Helper zu parsen und daraus die zu verwendenden Display Folder zu ermitteln.
Diese Display Folder werden dann in den – bereits bereitgestellten – Cube geschrieben. Um daraus wieder eine Solution zu erhalten, muss man dann nur noch eine neue Solution aus diesem Cube erstellen.
Ich halte den Weg sehr elegant, das Objektmodell zu verwenden. Allerdings halte ich das Parsen der Annotations für unelegant und fehleranfällig. Deswegen gehe ich einen anderen Weg:
Nachdem wir den migrierten Cube deployt haben, haben wir ja zwei Cubes in unserer Umgebung:
A: der alte Cube (z.B. SSAS 2012 / 2014) mit Display Folders (BIDS)
B: der neue Cube SSAS 2016 ohne Display Folder
Nun habe ich ein einfaches SSIS-Paket erstellt, das über DMVs (Dynamic Management Views) auf den alten Cube A zugreift und für alle Measures und (echte oder berechnete) Columns die Display Folder ausliest und sie dann über das Objektmodell, wie im vorletzten Beitrag beschrieben, in den neuen Cube schreibt.
Dabei verwende ich folgende DMVs:
$SYSTEM.MDSCHEMA_MEASURES für Measures: Dort interessieren mich alle Measures (MEASURE_NAME) und ihre Display Folder (MEASURE_DISPLAY_FOLDER), sowie der MEASUREGROUP_NAME. Im Tabular Model entspricht der MEASUREGROUP_NAME dem Tabellennamen. Als Cube filtern wir auf „Model“.
$System.MDSCHEMA_HIERARCHIES für Columns: Hier interessieren mich HIERARCHY_CAPTION, HIERARCHY_DISPLAY_FOLDER. Als Cube filtern wir auf alles außer „Model“. Dies funktioniert nur in den Versionen 2012 und 2014 (aber das ist hier ja genau der Fall). Dann tauchen nämlich alle Tabellen als CUBE_NAME auf – mit vorangestellten $ (also $Currency für Tabelle Currency). Jede Spalte steht dann in HIERARCHY_CAPTION.
Zu beachten ist, dass teilweise in deutschen Versionen der Cube nicht „Model“ sondern „Modell“ heißt. Dann müssen die Abfragen natürlich entsprechend angepasst werden.
Der Code zum Aktualisieren ist dann sehr einfach:
Der neue Cube (und Server) sind Variablen im SSIS-Paket.
Der Code verbindet sich darauf und holt dann das Model in die Variable _model.
Letzlich ist der Code dann nur: Table table = _model.Tables[tableName];
if (table.Measures.Contains(measureName))
{
Measure m = table.Measures[measureName];
m.DisplayFolder = displayFolder;
}
Und zum Abschluss (also im PostExecute) werden die Änderungen auf den Server gespielt: _model.SaveChanges();
Für Columns funktioniert es analog.
Im Übrigen habe ich auf einen Fehler verzichtet, falls ein Measure oder eine Column nicht im neuen Cube B vorhanden ist. Bei uns hatte das den Hintergrund, dass wir etliche Spalten / Measures für Fremdwährungen hatten, die wir per Code erstellten, so dass sie in A vorhanden, in B aber (noch) nicht vorhanden waren. Diese nicht in B gefundenen Spalten/Measures werden von dem jeweiligen Skript ausgegeben.
Zusammenfassend gehe ich also wie folgt vor:
1. Migration der Solution auf SSAS 2016 – dadurch gehen die Display Folders verloren
2. Deploy auf einen Entwicklungs-SSAS
3. Kopieren der Display Folder von der alten Cube-Instanz auf die neue
4. Erstellen einer neuen Solution aus dem nun fertigen Cube.
Das beschriebene ETL-Paket habe ich hier als zip inkl. Solution oder hier nur als dtsx-File hochgeladen. Um es zu verwenden, muss man die beiden Variablen mit den Infos zum 2016er Cube und die Connection auf den 2012er Cube anpassen.
Nachdem sich in SSAS 2016 im Hintergrund einiges geändert hat, wird die Verarbeitung eines Cubes nun mittels JSON-Syntax und nicht mehr XMLA ausgeführt, z.B. {
"refresh": {
"type": "automatic",
"objects": [
{
"database": "AMO2016Test"
}
]
}
}
Damit wird der Cube AMO2016Test verarbeitet.
(Ein solches Skript kann man sich wie gehabt im Management Studio über den Skript-Button in den Dialogen erzeugen lassen)
Grundsätzlich verwenden wir SSIS, um solche automatisierten Tasks durchzuführen (damit wir Standard-Features wie Protokolierung, Fehlerhandling etc. nutzen können).
Die Standard-Verarbeitungs-Komponente kann man nicht verwenden, da sie XMLA-basiert ist.
Aber man kann ganz einfach obigen Code in einer Execute-SQL-Task ausführen lassen, wenn man als Connection eine OLE-DB-Connection auf den Cube angelegt hat.
Es darf einen also nicht wundern, dass man einen JSON-Code in der Execute-SQL-Task ausführt. Da aber der Code einfach durchgereicht wird, ist klar, dass es funktioniert.
In einem Projekt erstellen wir Measures dynamisch: Für Währungen, die wir in einer relationalen Tabelle eintragen, werden automatisch Währungsumrechnungen aller Umsätze durchgeführt und dann im Cube automatisch angezeigt.
In SSAS vor der Version 2016 war das sehr kompliziert, da AMO (also das Objekt-Modell, auf das man via C# zugreifen konnte) noch dem MOLAP-Modell entspricht. Dort gab es also das Konzept z.B. berechneter Spalten nicht nativ. Deswegen gab es unter CodePlex ein AMO2Tabular-Projekt, mit dem versucht wurde, den Zugriff gekapselt zu ermöglichen.
In SSAS 2016 ist alles nun viel einfacher.
Hier ein Beispiel-Code (den wir in Integration Services eingebunden haten, da wir unsere Automatisierung als Teil unserer täglichen ETLs entwickelten):
Zunächst müssen Referenzen definiert werden:
AnalysisServices.Server.Tabular.dll
AnalysisServices.Server.Core.dll
Diese DLLs habe ich aus dem GAC genommen:
C:\Windows\Microsoft.Net\assembly\GAC_MSIL\Microsoft.AnalysisServices.Tabular\v4.0_14.0….. //using System.Data; - sonst ist DataColumn nicht mehr eindeutig
using Microsoft.AnalysisServices.Tabular;