Nachdem wir in einem Projekt unseren Test-Datenbestand (12 Mio Fakten) auf den Produktiv-Bestand (73 Mio Fakten) erweitert hatten, zeigten die Berichte (SSRS 2008 R2) massiv schlechte Antwortszeiten in bestimmten Berichten auf unseren Cube (SSAS 2008 R2) – jeweils nach der Cubeaufbereitung. Somit war klar, dass Ursache war, dass einige der im Bericht verwendeten Abfragen nicht im Cache waren, da dieser ja durch die inkrementelle Dimensionsaufbereitung und Aufbereitung einiger Cubepartitionen gelöscht wird.
Naheliegende Strategien waren:
- Aufteilung in mehr Partitionen unter Angabe der Slice-Property
- Verbesserte Aggregationen über Usage based Aggregation Design
- Cache Warming – Strategien
All das brachte uns aber nicht wirklich weiter.
Letztendlich stellte sich aber heraus, dass die Ursache gar nicht in den (tlw. komplexen) Abfragen zur Ermittlung der Fakten zu suchen war, sondern in „Dimensions-Abfragen“. Damit meine ich folgendes: Unsere Berichte werden (aus einer eigenen Web-Applikation heraus) mit Parametern aufgerufen, die IDs sind (eigentlich die Member Unique Names, also z.B. Datum.Jahr.&[2010]). Dabei haben die Parameter (aus Performancegründen) keine Datasets, die alle verfügbaren Werte enthalten. Nun wollen wir aber in dem Bericht natürlich auch den übergebenen Wert im Klartext anzeigen, also in obigem Beispiel das Jahr 2010. Deswegen mussten also einfache Abfragen her, die aus dem Member Unique Name den Klartext (Member Caption) ermitteln.
In unserem Projekt hatten wir uns darauf geeinigt, wenn möglich den SSRS-Designer für SSAS-Abfragen zu verwenden, um eine gute Wartbarkeit (ohne tiefere MDX-Kenntnisse) zu erreichen.
Damit gibt es zwei einfache Arten, dieses Problem zu lösen:
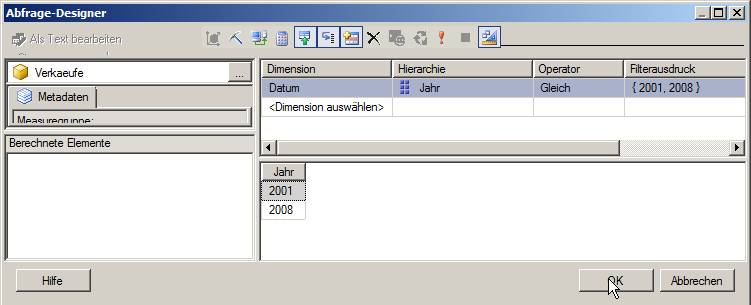
Die erste Art, hat eine Spalte – das Jahr – und zusätzlich den (MultiSelect) Report Parameter als Parameter für die Abfrage:
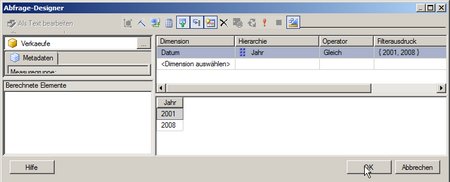
(Bild zum Vergößern anklicken!)
Als MDX ergibt sich:
SELECT { } ON COLUMNS, { ([Datum].[Jahr].[Jahr].ALLMEMBERS ) } DIMENSION PROPERTIES MEMBER_CAPTION, MEMBER_UNIQUE_NAME ON ROWS FROM ( SELECT ( STRTOSET(@DatumJahr, CONSTRAINED) ) ON COLUMNS FROM [Verkaeufe]) CELL PROPERTIES VALUE
Man kann auch die Abfrage etwas erweitern:
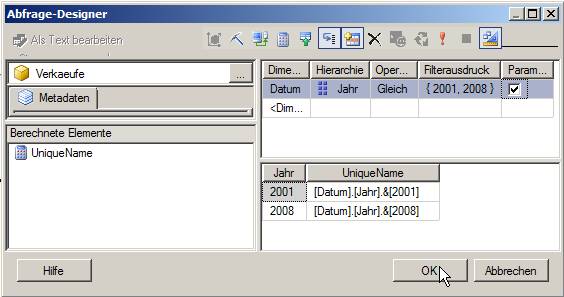
Man fügt ein berechnets Measure (in diesem Fall namens „UniqueName“) mit dem MDX
[Datum].[Jahr].CurrentMember.UniqueName
hinzu:
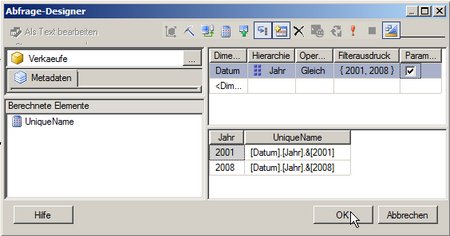
(Bild zum Vergößern anklicken!)
Damit ergibt sich folgendes MDX:
WITH MEMBER [Measures].[UniqueName] AS [Datum].[Jahr].CurrentMember.UniqueName SELECT NON EMPTY { [Measures].[UniqueName] } ON COLUMNS, NON EMPTY { ([Datum].[Jahr].[Jahr].ALLMEMBERS ) } DIMENSION PROPERTIES MEMBER_CAPTION, MEMBER_UNIQUE_NAME ON ROWS FROM ( SELECT ( STRTOSET(@DatumJahr, CONSTRAINED) ) ON COLUMNS FROM [Verkaeufe]) CELL PROPERTIES VALUE, BACK_COLOR, FORE_COLOR, FORMATTED_VALUE, FORMAT_STRING, FONT_NAME, FONT_SIZE, FONT_FLAGS
Anmerkung: Das dabei enstehende versteckte Dataset zum Befüllen der „verfügbaren Werte“ des Parameters löschen wir, da wir ja keine „verfügbaren Werte“ anzeigen wollen (unsere Dimension hatte zu viele Einträge).
Beide Abfragen scheinen dasselbe zu tun und mit der selben Performance. Dies ist aber ein Trugschluss!
Leeren wir zunächst (und vor Ausführung eines neuen Test-Statements) den SSAS-Cache mit
<ClearCache xmlns=“http://schemas.microsoft.com/analysisservices/2003/engine“>
<Object>
<DatabaseID>SimpleCube</DatabaseID>
<CubeID>Verkaeufe</CubeID>
</Object>
</ClearCache>
(siehe dazu auch: http://www.ssas-info.com/analysis-services-faq/27-mdx/133-mdx-how-do-i-clear-analysis-services-ssas-database-cache)
Dann betrachten wir die Darstellung im SQL Server Profiler (mit den Standard-Einstellungen für den SSAS):
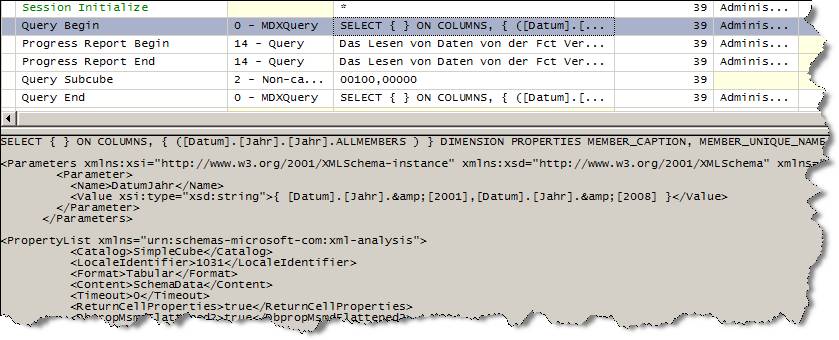
Die erste Abfrage ergibt folgendes Bild:
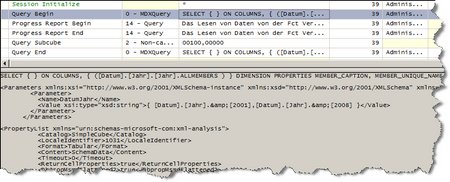
(Bild zum Vergößern anklicken!)
Schauen wir uns die einzelnen Zeilen an:
- Session Initialize – spricht für sich
- Query Begin: Hier fängt die Abfrage an – im unteren Bereich sieht man das MDX und die Parameterwerte für die @Parameter im MDX
- Progress Report Begin: Daten aus einer Partition werden gelesen (!), d.h. von der Festplatte in den Speicher übernommen.
- Progress Report End: das dazugehörige Ende
- Query SubCube: die gelesenen Daten werden verwendet, um die Abfrage zu beantworten (in diesem Fall Non-Cache)
- Query End: Das Ende der Abfrage
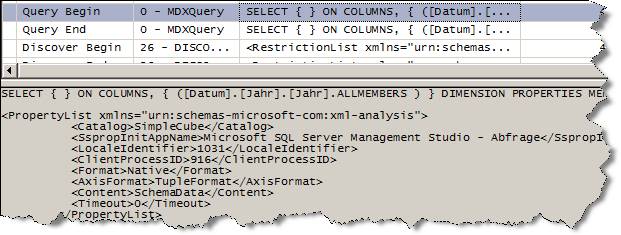
Die zweite Abfrage ergibt ein anderes Bild:

(Bild zum Vergößern anklicken!)
Hier sehen wir, dass kein Zugriff auf eine Partition erfolgt!
Der Zugriff auf die Partition ist natürlich schädlich, da er bei großen Datenmengen lang dauern kann, zumal er gar nicht benötigt wird, da wir ja nur Dimensions-Element-Bezeichnungen abfragen wollen.
Es ist nicht erklärbar, warum SSAS hier dennoch auf die Fakten zugreift.
Deswegen ist die zweite Abfrage auf jeden Fall vorzuziehen!
Noch ein interessante Anmerkung zum Schluss: Wenn man die erste Abfrage im SQL Server Management Studio ausführt, ist sie auch nicht langsam. Da im Management Studio keine parametrisierten Abfragen möglich sind, muss man dazu die Parameter durch die entsprechenden Strings ersetzen, und erhält somit folgendes MDX:
SELECT { } ON COLUMNS, { ([Datum].[Jahr].[Jahr].ALLMEMBERS ) } DIMENSION PROPERTIES MEMBER_CAPTION, MEMBER_UNIQUE_NAME ON ROWS FROM ( SELECT ( STRTOSET(„{ [Datum].[Jahr].&[2001],[Datum].[Jahr].&[2008] }“, CONSTRAINED) ) ON COLUMNS FROM [Verkaeufe]) CELL PROPERTIES VALUE
Führt man dieses MDX aus (nachdem man den Cache geleert hat), so erhält man folgendes Bild:
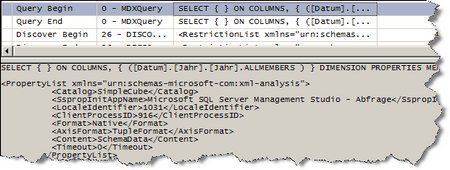
(Bild zum Vergößern anklicken!)
Man sieht hier also auch nur ein Query Begin und ein Query End, also auch keinen Zugriff auf die Cube-(bzw. Partitions-)Daten.
Dies hatte uns die Fehlersuche erschwert, da wir natürlich zunächst auf der Suche nach dem verantwortlichen Statement alle Statements im SQL Server Profiler mitgeschnitten und dann einzeln im Management Studio ausgeführt hatten, was – wie eben gesehen – das problematische Statement leider nicht offenbart.