Es kommt ja ab und zu vor, dass man einen String nach einem Trennzeichen splitten will und dann aus einer Zeile mehrere Zeilen machen will.
Problem: Einen String Splitten
Beispielsweise möchte man aus dem String
A|B|C|D
die Tabelle
| A |
| B |
| C |
| D |
machen.
EVALUATE
VAR txt = "A|B|C|D"
RETURN
ADDCOLUMNS (
GENERATESERIES ( 1, PATHLENGTH ( txt ) ),
"Spalte", PATHITEM ( txt, [Value], TEXT )
)
liefert
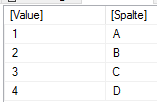
Das ist also die Lösung des Problems. Natürlich kann man noch die Value-Spalte löschen, z.B. mit SELECTCOLUMNS.
Wir haben uns hier folgendes zu nutze gemacht:
- Wenn man als Trenner | verwendet, kann man die eingebauten Funktionen PATHITEM, PATHLENGTH verwenden
- Wenn man einen anderen Trenner verwendet, kann man ggf. den Trenner durch | ersetzen
- GENERATESERIES erzeugt eine einspaltige Tabelle (Spalte heißt Value) mit Zahlen von 1 bis n
Für Fortgeschrittene: Einen String in einer Tabelle splitten
Im obigen Beispiel haben wir einen Text gesplittet. Nun kann es aber sein, dass man in einer Tabelle eine Spalte hat, die man splitten will und dann entsprechend mehr Zeilen bekommen will.
Also z.B. aus der Tabelle
| Key | Text |
| David | A|B |
| Peter | C|D|E|F |
möchte man die Tabelle
| Key | Zelle |
| David | A |
| David | B |
| Peter | C |
| Peter | D |
| Peter | E |
| Peter | F |
machen.
Im SQL würde man dazu CROSS APPLY verwenden.
In DAX geht es wie folgt:
EVALUATE
VAR tabelle =
UNION (
ROW ( "Key", "David", "Text", "A|B" ),
ROW ( "Key", "Peter", "Text", "C|D|E|F" )
)
RETURN
SELECTCOLUMNS (
ADDCOLUMNS (
GENERATE ( tabelle, GENERATESERIES ( 1, PATHLENGTH ( [Text] ) ) ),
"Spalte", PATHITEM ( [Text], [Value], TEXT )
),
"Key", [Key],
"Zelle", [Spalte]
)
Gehen wir die einzelnen Schritte durch:
Zunächst erstelle ich die Ausgangstabelle wie oben. Dies steht dann in der Variable tabelle:
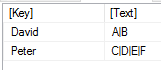
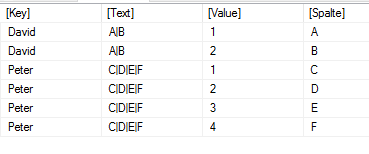
Das GENERATE führt dann für jede Zeile die GENERATESERIES – Funktion aus. Dort steht der jeweilige Text aus der Zeile. Die PATHLENGTH ist also für die erste Zeile 2, für die zweite 4. Das Ergebnis vom GENERATE ist somit:

Über das Addcolumns holen wir uns die jeweilige Stelle aus dem zu splittenden String:
Und das Ergebnis des gesamten DAX Statements ist:
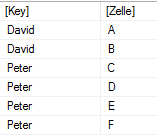
Also genau das, was wir zeigen wollten 🙂