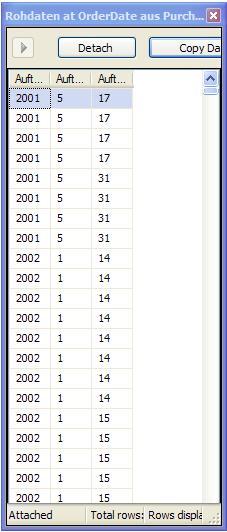
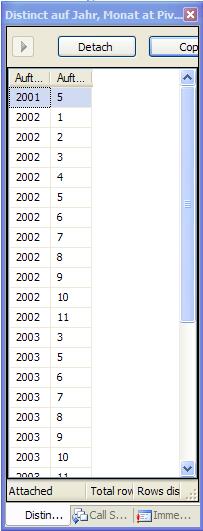
Der SQL-Server unterscheidet (im Standard) bei den Daten nicht zwischen Groß- und Kleinschreibung.
Gerade für versierte SQL-Entwickler führt dies bei der Verwendung der Integration Services zu Schwierigkeiten, da Integration Services sehr wohl zwischen Groß- und Kleinschreibung unterscheidet. Somit verhalten sich SSIS-Transformationen leicht anders als ihre SQL-Pendants:
Ich möchte auf die SSIS-Transformationen Aggregation (Aggregate) und die Suche (Lookup) [im nächsten Blog-Eintrag] eingehen:
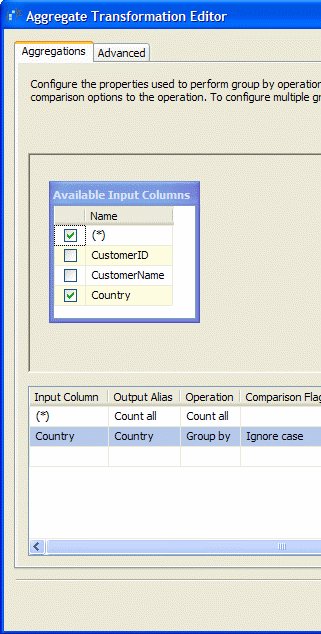
Zunächst vergleiche ich die SSIS-Transformation Aggregate mit dem SQL-Befehl GROUP BY:
Als Ausgangsdaten verwende ich die Tabelle Customers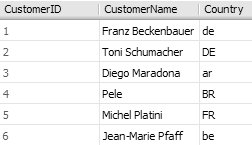
Damit liefert das SQL-Statement
SELECT Country, count(*) as Anzahl
FROM Customers
Group by Country
folgendes Ergebnis (de=DE im SQL Server):
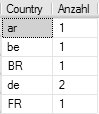
Die naheliegende SSIS-Transformation liefert aber (de <> DE im SSIS):
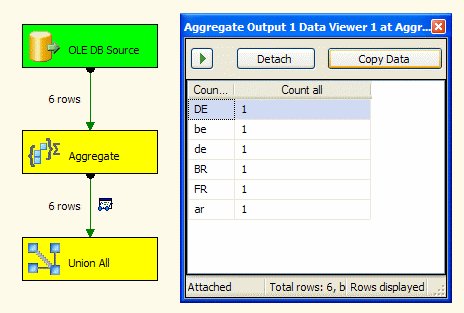
Hierbei habe ich das Standard-Verhalten der Tools dargestellt. Man kann aber in beiden Produkten ein gleiches Verhalten erzeugen:
-
Im SQL Server könnte man die Collation Spalte ändern, so dass die Werte auch Groß- und Kleinschreibung unterscheidet, also zum Beispiel Latin1_General_CS_AS
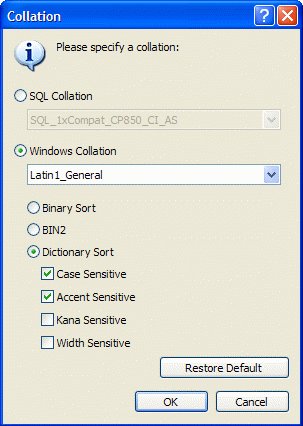
Diese Änderung betrifft natürlich die komplette Tabelle und somit alle Abfragen auf diese Tabelle! -
Wenn man nur diese eine Abfrage im SQL auf „Beachte Groß- und Kleinschreibung“ setzen will, so kann man folgendes Statement verwenden:
SELECT Country , count(*) as Anzahl
FROM (select country COLLATE Latin1_General_CS_AS as Country, CustomerName FROM Customers) as tab
Group by Country
Ohne die Verwendung von Derived Tables (dem obigen „SubSelect“) bzw. Common Table Expressions geht es nicht. Ein Statement wie
SELECT Country COLLATE Latin1_General_CS_AS, count(*) as Anzahl
FROM Customers
Group by Country
liefert also immer noch 5 Zeilen. -
In der SSIS-Transformation Aggregate kann man einstellen, dass die Groß- und Kleinschreibung ignoriert werden soll: