Gestern habe ich beschrieben, welche Unterschiede zwischen SQL Server und SSIS bei Groß- und Kleinschreibung bei der Aggregation zu beachten sind.
Natürlich ist das Verhalten der beiden Produkte konsistent:
- SQL Server unterscheidet grundsätzlich (im Standard) nicht zwischen Groß- und Kleinschreibung
- SSIS unterscheidet grundsätzlich (im Standard) zwischen Groß- und Kleinschreibung
Damit ist auch klar, dass andere Transformationen von Unterschieden betroffen sind. Heute betrachte ich die SSIS-Transformation Lookup (Suche):
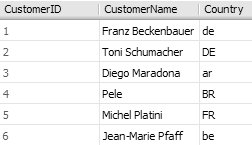
Als Beispiel verwende ich wieder die Tabelle Customers
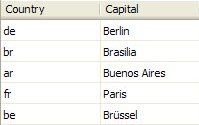
und die neue Tabelle Countries
Eine Anmerkung zu diesem Beispiel: Die Verwendung von Strings für Schlüssel liefert mir ein einfaches Besipiel, soll aber natürlich nicht als Standard für die Datenmodellierung angesehen werden 🙂
Der SSIS-Data Flow soll nun alle Kunden mit zugehöriger Hauptstadt ermitteln.
Die Lookup-Transformation funktioniert auf zwei unterschiedliche Arten:
- komplettes Laden der Lookup-Tabelle (hier Countries) vor dem Start der Ausführung des eigentlichen Data Flows – dies ist der Standard
- Einzelnes Laden der nachzuschlagenden Datensätze – wenn man unter dem 3. Reriter (Advanced) den Haken bei „Enable memory restriction“ aktiviert.
Ich beginne mit dem zweiten:
Einzelnes Laden der nachzuschlagenden Datensätze:
Die Einstellungen für die einzelnen Reiter der Lookup-Transformation sind wie folgt:
- Reference Table: verwende Tabelle Countries
- Columns: Der Join geht über Country — Country. Als zusätzliche Spalte wird Capital ausgegeben
- Advanced: Wir setzen den Halen bei „Enable memory restriction“. Der Rest bleibt im Standard (keine weiteren Haken)
Als Ergebnis erhalten wir:
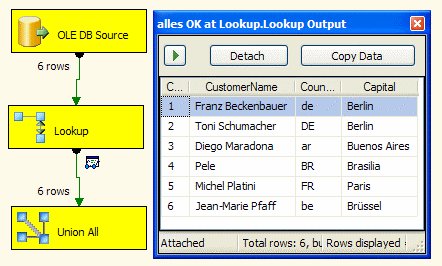
Das liefert also das gewünschte Ergebnis.
Wie geht hier SSIS intern vor?
Für jede Zeile wird ein SQL-Statement ausgeführt, das zu der Country die Capital dazuliest (Also z.B. SELECT * FROM Countries WHERE Country = ‚de‘) [Das genaue SQL-Statement sieht man im Bereich „Caching SQL-Statement“ auf dem 3. Reiter (Advanced)].
Da der SQL Server nicht zwischen Groß- und Kleinschreibung unterscheidet, unterscheidet also auch diese Version der Lookup-Transformation nicht.
Natürlich ist aber dieses Vorgehen bei großen Datenmengen imperformant, da für jede Zeile ein SQL-Select ausgeführt wird. Daran ändern auch die weiteren Optionen unter Advanced nichts (grundlegendes): Enable Caching würde nur verhindern, dass nicht zweimal dasselbe SQL-Statement ausgeführt wird (Wenn also „de“ in zwei Zeilen auftauchen würde). Der Cache selbst wäre im übrigen wieder case-sensitive (D.h. unterscheidet zwischen Groß- und Kleinschreibung) – es würden also für „de“ und „DE“ zwei SELECTs ausgeführt.
Deswegen jetzt die Betrachtung der Standard-Methode des Lookups:
komplettes Laden der Lookup-Tabelle
Wir entfernen den Haken „Enable memory Restriction“ im Tab „Advanced“ und starten das Paket nochmals.
Sofort erhalten wir einen Fehler, dass der Lookup keinen Treffer findet. Durch Erweitern des Data Flows sehen wir die nicht gefundenen Datensätze:
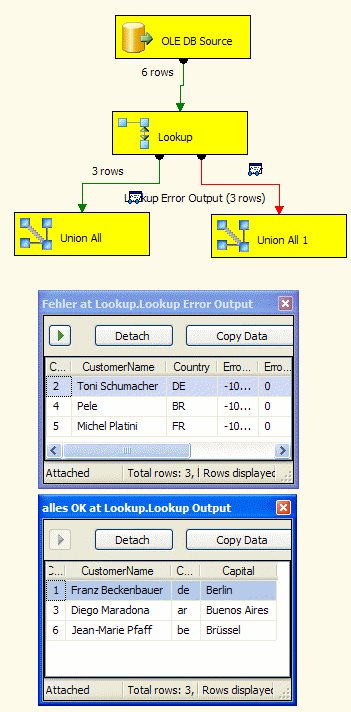
Wir sehen also, dass der Lookup im Standard Groß- und Kleinschreibung unterscheidet.
Wie kann man dieses Problem umgehen?
Man kann natürlich die verwendeten Spalten vor dem Zugriff auf Großbuchstaben konvertieren:
- Im SSIS durch das Einfügen einer derived Column, die mittels UPPER( [Country]) entweder eine neue Spalte erzeugt oder die bestehende überschreibt.
- Im SQL-Statement für den Referenz-SELECT durch UPPER(), z.B. SELECT Upper(Country) as CountryUpper, * from countries
Natürlich gibt es noch andere Möglichkeiten zum Umgehen des Problems wie Fehlerhandling. Das erscheint mir hier aber konstruiert.
siehe auch meinen Blog-Eintrag zur binären Collation bei der Suche: http://csopro.de/biblog/2009/03/ssis-binaere-collation-bei-der-suche/