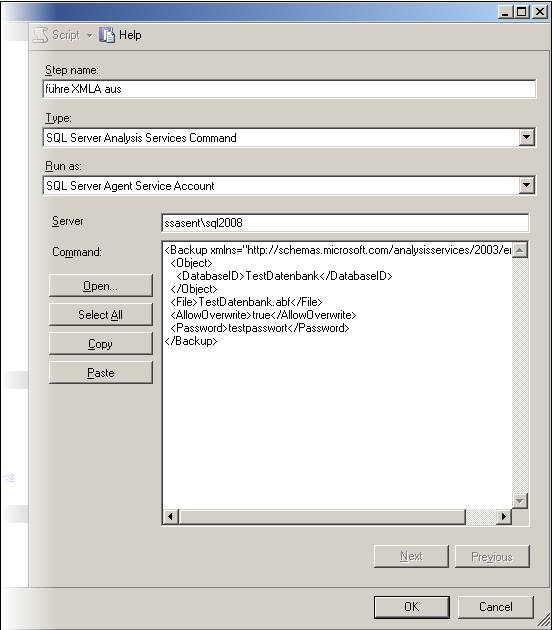
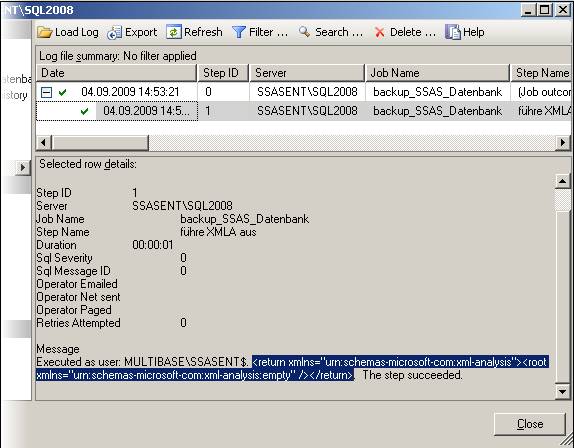
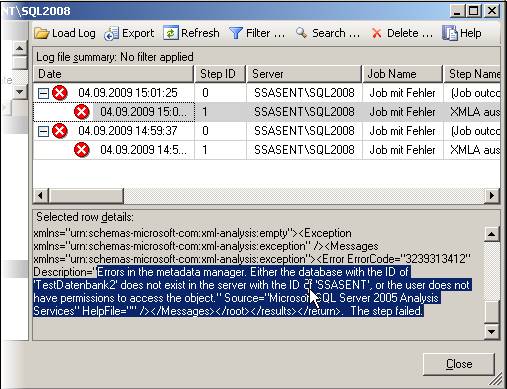
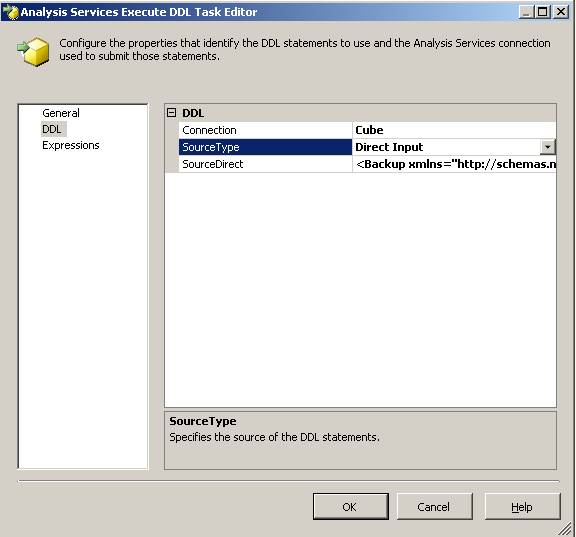
Eine Möglichkeit, eine Dimension relational abzubilden, ist ein Snowflake-Schema. In diesem Schema werden Hierarchien so abgebildet, dass jede Hierarchiestufe eine eigene Tabelle besitzt, die durch Foreign Keys verbunden sind.
Probleme können auftreten, wenn nicht bei allen Dimensionselementen alle Ebenen vorhanden sind und deshalb manche Elemente in der Datenbank NULL sind. Diese können über das Setzen der Eigenschaft „NULL Processing“ gelöst werden. Fangen wir aber vorne an.
Ein Beispiel für eine Dimension im Snowflake-Schema seien die Hierarchien Produkt > Warengruppe > Strategisches Geschäftsfeld (SGF) und Produkt > Produktionskennzeichen (hier ein Screenshot des Data Source View):
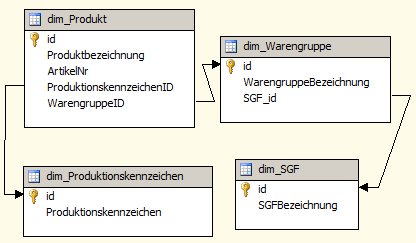
Daraus lässt sich einfach eine Dimension bauen:
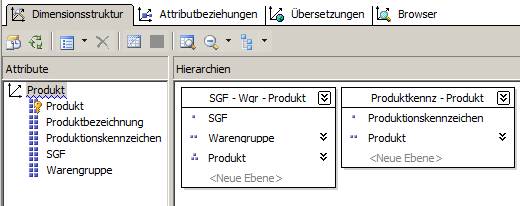
(Zum Vergrößern Bild anklicken)
Die einzelnen Attribute sind so definiert: Die Key-Column ist jeweils die ID-Spalte (also zum Beispiel id aus der Tabelle dim_SGF), die Name-Column jeweils die zugehörige Bezeichnung (z.B. die Tabelle SGFBezeichnung der Tabelle dim_SGF).
In meinem Beispiel kann die Produktionskennzeichen_ID der dim_Produkt NULL sein.
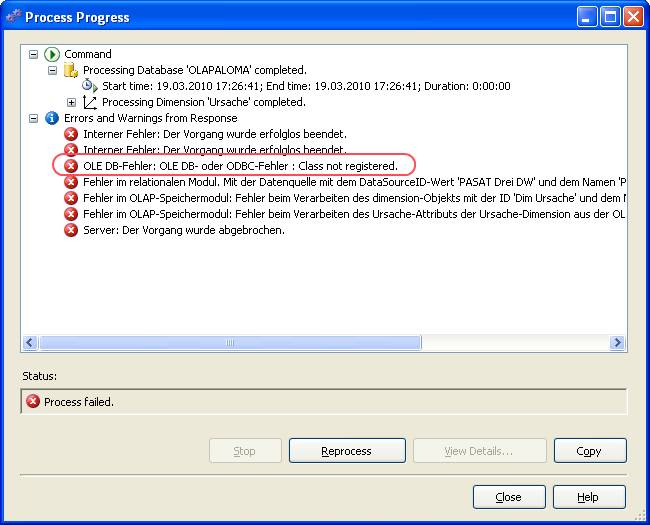
Das hätte jetzt zur Folge, dass – Stand jetzt – die Dimension nicht aufbereitet werden kann:
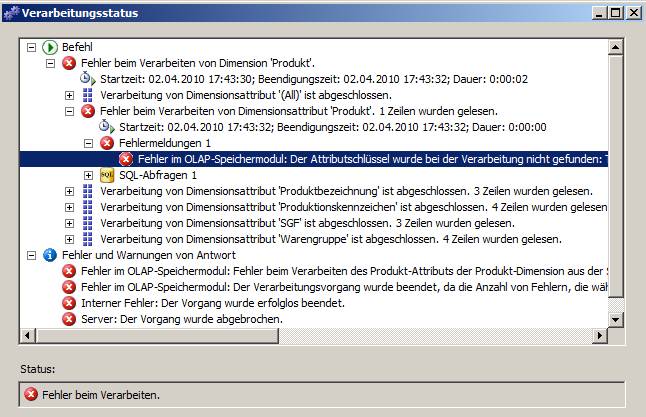
(Zum Vergrößern Bild anklicken)
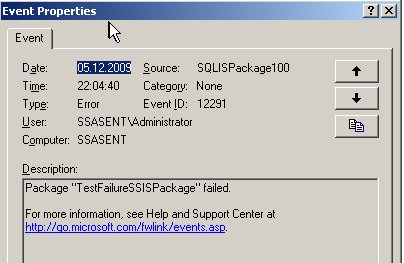
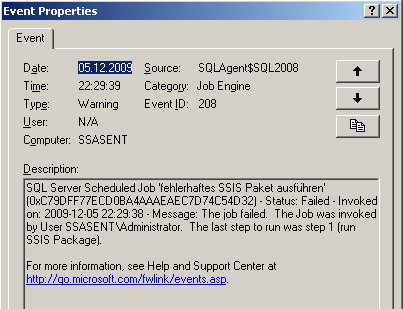
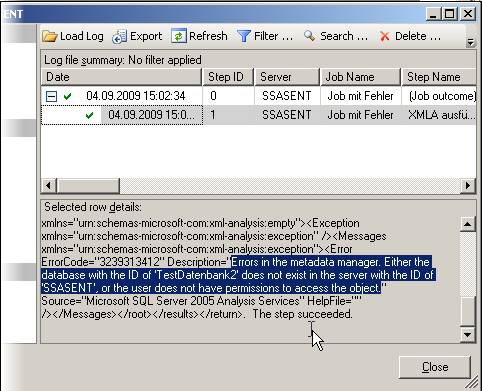
Die Fehlermeldung im Detail:
Fehler im OLAP-Speichermodul: Der Attributschlüssel wurde bei der Verarbeitung nicht gefunden: Tabelle: dbo_dim_Produktionskennzeichen, Spalte: id, Wert: 0. Das Attribut ist ‚Produktionskennzeichen‘. Fehler im OLAP-Speichermodul: Fehler beim Verarbeiten des Produkt-Attributs der Produkt-Dimension aus der SimpleCube-Datenbank.
Offensichtlich hat der SSAS den NULL-Wert als 0 interpretiert, was er natürlich nicht finden kann.
Die Lösung ist:
-
Definieren des Unknown-Members der Dimension als sichtbar mit der Bezeichnung „unbekannt“ (oder wie auch immer)
-
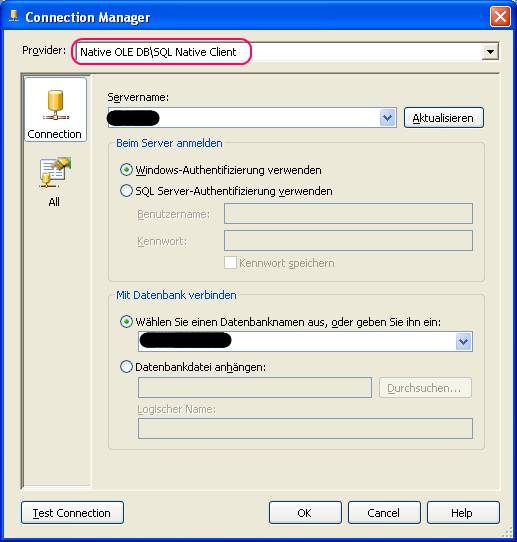
Definieren der Nullprocessing-Eigenschaft der Key Column von Produktionskennzeichen auf „ConvertToUnknown“:
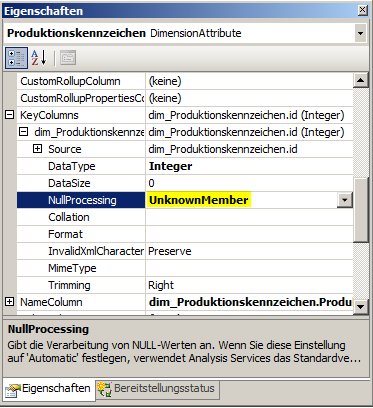
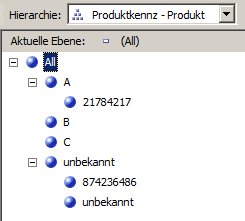
Dann funktioniert die Aufbereitung und die Dimensionen sehen in meinem Beispiel so aus (die Zahlen sind irgendwelche Artikelnummern 🙂 ):
Hierarchie SGF:
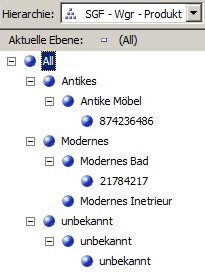
Hierarchie Produktionskennzeichen:
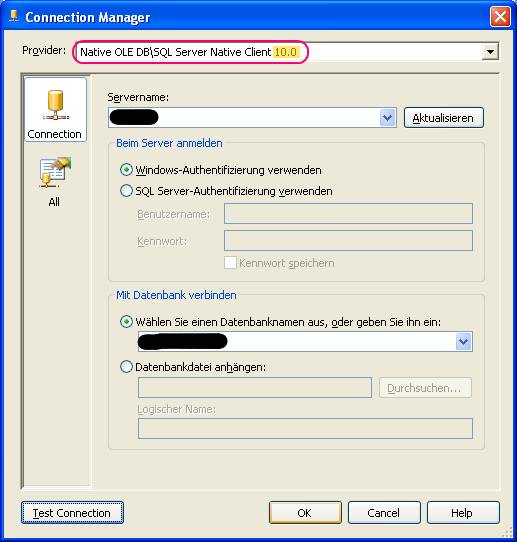



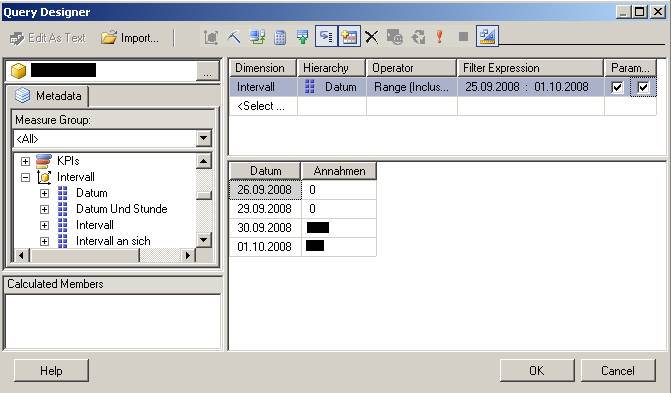
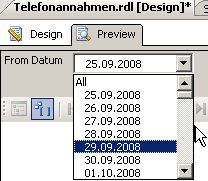
 klicken)
klicken) ):
):
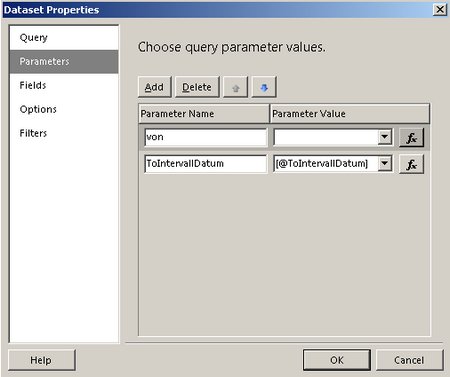
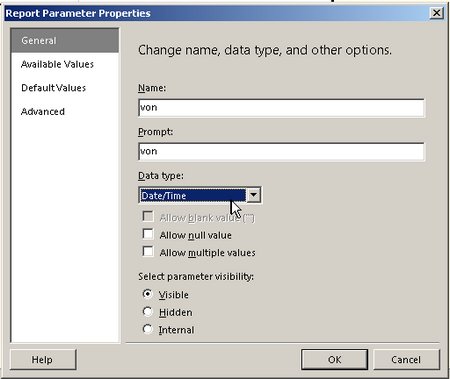
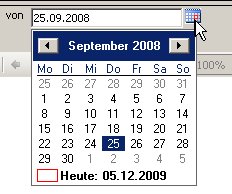
 , den wir wie folgt bearbeiten: Wir setzen den Datentyp auf Datetime:
, den wir wie folgt bearbeiten: Wir setzen den Datentyp auf Datetime: