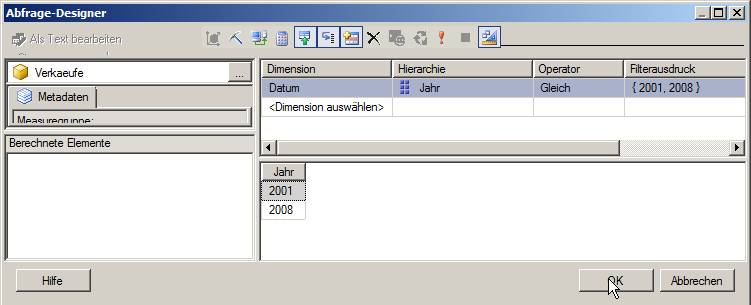
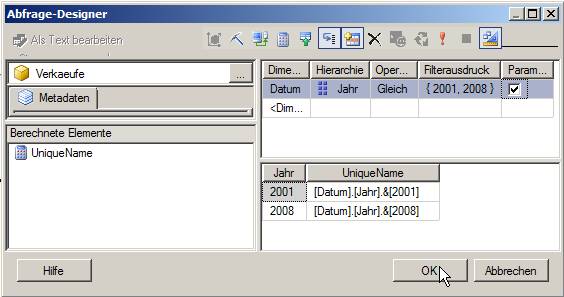
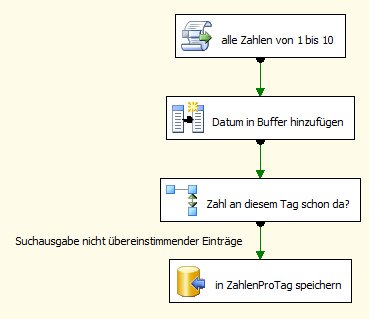
Lookups kommen bei SSIS-Data Flows ziemlich häufig vor. Zum Beispiel müssen bei der Verarbeitung von Fakten-Sätzen enthaltene Dimensions-Referenzen umgesetzt werden. Zum Beispiel könnte es sein, dass Deutschland im Quellsystem ‘D’ ist, im DWH aber mit 49 abgebildet wird.
Das ist mit Lookups natürlich ganz einfach.
Nun kommt es aber vor, dass nicht alle Fakten eine Referenz auf ein Land haben müssen, also NULL sind. Diese sollen dann auch NULL bleiben.
Wie kann eine solche Aufgabe gelöst werden?
Die Standard-Lösung wird so aussehen:
Vor dem Lookup wird über einen Conditional Split überprüft, ob das Land leer ist:
- Wenn ja, dann wird der Zielwert auch auf NULL gesetzt
(Dafür muss nichts gemacht werden, da dies beim folgenden UNION ALL automatisch erfolgt) - Wenn nein, dann wird der Lookup durchgeführt
Danach werden beide Pfade über einen UNION wieder zusammengeführt:

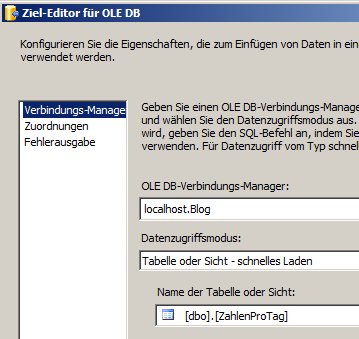
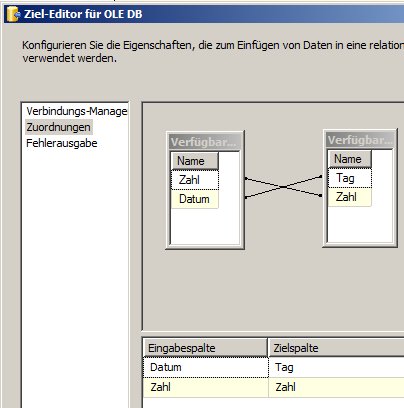
In meinem Beispiel sieht die Lookup-Quelle so aus:
SELECT N’D‘ as Country, 49 as nummer
UNION ALL
SELECT N’A‘ as Country, 43 as nummer
UNION ALL
SELECT N’CH‘ as Country, 41 as nummer
Diese Vorgehensweise hat mehrere Nachteile:
- Über das UNION ALL wird immer ein neuer Buffer angelegt, was insbesondere bei großen Data Flows unnötig Speicher belegt (UNION ALL ist semi-blocking)
- Die Lösung ist einigermaßen komplex
- Falls eine Sortierung vorliegt, geht die Sortierung durch das UNION ALL verloren. Dies sollte nicht durch den Einsatz eines MERGE verhindert werden, da dies die Performance sehr negativ beeinflussen kann (vielleicht schreibe ich dazu mal einen eigenen Blog-Eintrag)
Deswegen hatten wir nach einer besseren Lösung gesucht:
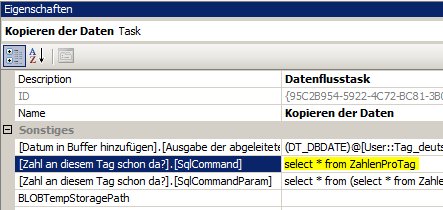
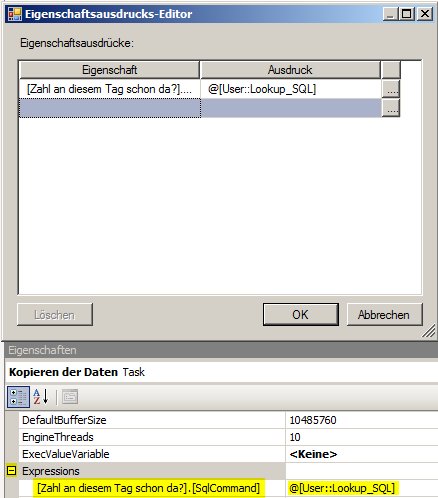
Der erste Ansatz war folgender: Wir können beim Lookup Nicht-Treffer ignorieren und danach überprüfen, ob wir ein Mapping übersehen haben und dann selbst einen Fehler schmeißen:
 Der Conditional Split enthält folgende Bedingung:
Der Conditional Split enthält folgende Bedingung:
!(ISNULL(Country)) && ISNULL(nummer)
In der Skriptkompopnente wird ein Fehler mit folgendem Code erzeugt:
public override void Input0_ProcessInputRow(Input0Buffer Row)
{
bool p=false;
ComponentMetaData.FireError(10, „Testkomponente“, „Country was not null, but could not be mapped to a country number“, „“, 0, out p);
}
Dieser Ansatz hat folgenden Vorteil:
- Alle Komponenten sind synchron, benötigen also keine zusätzlichen Buffer.
– aber auch folgende Nachteile:
- Die Lösung ist noch komplexer
- Die Lösung ist unübersichtlich und schlechter wartbar, da ohne die Skriptkomponente der Lookup falsch programmiert wäre. Das muss aber der wartende Mitarbeiter wissen. Außerdem ist ein Error Handling “Fehler ignorieren” irreführend.
- Skript-Komponenten haben selbst keinen Fehler-Output. Damit kann eine Skript-Komponente leider nicht mit der vorhin vorgestellten Quarantäne-Idee automatisch korrigiert werden.
Die beste Lösung ist somit eine ganz einfache:
Wir stellen den Lookup wieder auf Fehler bei einem Nicht-Treffer. Wir ergänzen die Quelle des Lookups um NULL-Werte, also in meinem Beispiel
SELECT N’D‘ as Country, 49 as nummer
UNION ALL
SELECT N’A‘ as Country, 43 as nummer
UNION ALL
SELECT N’CH‘ as Country, 41 as nummer
UNION ALL
SELECT NULL, NULL
bzw. allgemein
SELECT * FROM <lookup-tabelle>
UNION ALL
SELECT NULL, NULL
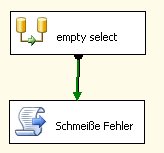
Dann sieht der Data Flow ganz einfach aus:

Dies hat natürlich etliche Vorteile:
- Die Lösung ist super-einfach.
- Die Lösung ist natürlich synchron und somit sehr schnell.
Allerdings funktioniert diese Lösung nur, wenn Full Cache eingestellt ist:

Dies ist aber eh die meistens verwendete (da performanteste) Variante.
Die Ursache, warum die anderen Cache-Einstellungen nicht funktionieren, liegt darin, dass im SQL NULLs anders verwendet werden (sie können nicht mit = abgeprüft werden). In den anderen Cache-Einstellungen würden SQLs wie SELECT * FROM <lookuptabelle> where Country = NULL ausgeführt.