In einem Projekt, in dem die gesamte Datenhaltung und Datenverarbeitung on premise war (SQL + SSIS), haben wir einen Azure Analysis Services-Cube benutzt.
Für die Verarbeitung dieses Cubes haben wir nach einfachen Wegen gesucht, wie wir die Cube-Verarbeitung von SSIS / SQL Agent aus anstarten könnten.
Aber für unseren Fall wollten wir eine möglichst einfache Lösung innerhalb SSIS.
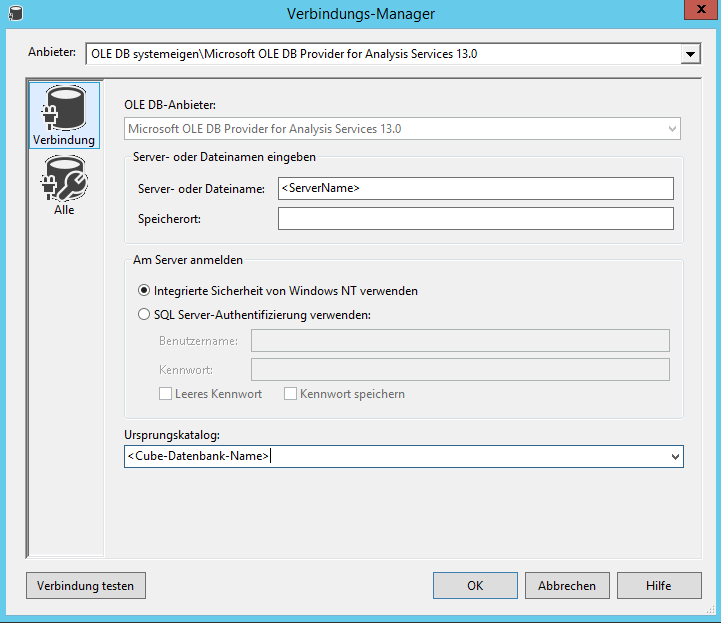
Zunächst schauen wir uns an, wie wir einen On-Prem-Analysis-Services-Cube verarbeiten würden. Dazu reicht im SSIS eine Execute-SQL-Task mit folgenden Einstellungen:
Connection ist eine OLE DB-Connection, z.B. mit folgendem Connection-String: Data Source=<ServerName>;Initial Catalog=<Cube-Datenbank-Name>;Provider=MSOLAP.7;Integrated Security=SSPI;
Connection auf SSAS
Im Feld „SQL-Statement“ trägt man den SSAS-Befehl ein (den man sich z.B. im SQL Server Management Studio skripten lassen kann):
Für eine Verarbeitung eines Azure-Cubes können wir ganz genauso vorgehen. Nur der ConnectionString ist zu ändern:
Als Data Source ist der Azure Analysis Service einzutragen, also irgendwie so: asazure://westeurope.asazure.windows.net/<Server>
Wir müssen einen User angeben, da wir nicht den User verwenden können, unter dem der Prozess on prem läuft. Also sieht unser ConnectionString so aus: Data Source=asazure://westeurope.asazure.windows.net/<Server>;User ID=<Username>@<Azure Active Directory>;Initial Catalog=<Cube-Datenbank-Name>;Provider=MSOLAP.8;Persist Security Info=False;
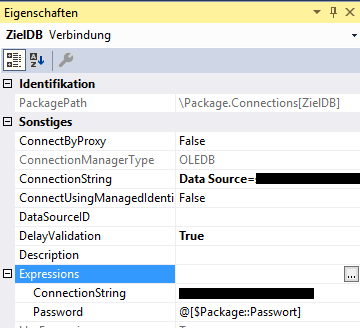
Dann müssen wir in dem Attribut Password der Connection das Passwort dieses Users mitgeben.
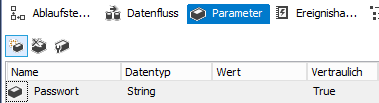
Natürlich wollen wir das Passwort nicht im plain text irgendwo stehen haben. Deswegen reichen wir das Passwort über einen Paket-Parameter herein, den wir als sensitive (vertraulich) definieren. Dann können wir bei der Konfiguration im Katalog oder im SQL Server Agent das Passwort eintippen und es ist sicher in der SSISDB gespeichert:
Im Paket sieht das so aus:
Paket-Parameter „Passwort“ – als vertraulich definiertEigenschaften der SSAS-Connection in SSIS
In diesem Fall habe ich sogar den Connection-String auch noch von außen hereingereicht.
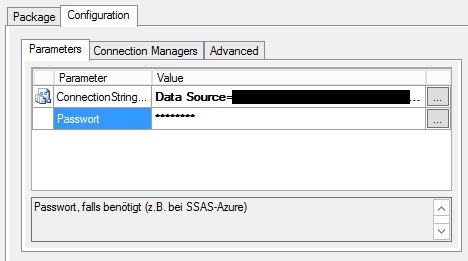
Bei der Konfiguration im SQL Agent stellt man dann das Passwort ein:
Konfiguration des Paket-Aufrufs im SQL Server Agent mit Passwort-Eingabe
Damit können wir mit dem gleichen Code lokale und Azure-Analysis-Services-Cubes verarbeiten – lediglich den Connectionstring mussten wir anpassen und im Azure-Analysis-Services-Fall das Passwort mit angeben.
Dies hat folgende Vorteile:
einheitliche Code-Basis – ein Code für beides
Passwort sicher gespeichert
im Gegensatz zu obiger Azure Data Factory-Variante
der User benötigt nur process-Rechte auf dem Cube
Der Aufruf ist automatisch synchron, so dass man Fehler einfach mitbekommt.
In meinen Projekten kommt es natürlich oft vor, dass man Datumsdimensionen benötigt.
Dazu verwende ich Stored Functions im SQL Server, um die Datumswerte mit allen gewünschten Attributen (wie Wochentag, Monat, Kalenderwoche, etc.) an den Analysis Services-Dienst weiter zu geben. Ich will das hier beschreiben, weil seit SSAS 2017 der Aufruf von Stored Functions gar nicht mehr so offensichtlich ist (wenn man die depracted Data Sources nicht verwenden will).
Das Vorgehen ist wie folgt:
Ermittle die Datumswerte, die die Datumsdimension enthalten soll. In der Regel ist das entweder ein Zeitraum oder distinkte Werte (z.B. bei einer Dimension, in der der Datenstand ausgewählt werden kann)
Liefere zu den ermittelten Datumswerten alle Attribute wie Wochentag, Monat, Kalenderwoche, etc.)
Gib diese Daten an den SSAS weiter
Wir benutzen hier bewusst einen getrennten Ansatz, erst die anzeigenden Datumswerte zu ermitteln und dann dazu die Attribute zu erzeugen. Dadurch erreichen wir die höchst mögliche Flexibilität. Man könnte zum Beispiel folgendes machen:
Wir nehmen alle Datumswerte vom Minimum der auftretenden Werte bis zum Maximum
Da aber Fehleingaben enthalten sind, und wir nicht alle Datumswerte vom 1.1.2000 bis 1.1.3000 in unserer Dimension haben wollen, nehmen wir nur die Datumswerte vom Minimum bis zum Ende nächsten Jahres und alle weiteren DISTINCTen Werte, die vorkommen.
Wir gehen so vor:
Als erstes legen wir einen Type an, der eine Liste von Datumswerten halten kann:
CREATE TYPE [dbo].[typ_Datumswerte] AS TABLE(
[datum] [date] NOT NULL,
PRIMARY KEY CLUSTERED
(
[datum] ASC
)WITH (IGNORE_DUP_KEY = OFF)
)
GO
In eine Variable dieses Datentyps können wir nun beliebige Datumswerte speichern. Wenn man zum Beispiel eine distinkte Menge an Datumswerten aus einer Faktentabelle speichern will, kann man das so machen:
DECLARE @d AS typ_Datumswerte
INSERT INTO @d SELECT DISTINCT Datum FROM Fakt_Auftragsbestand
Meistens benötigt man aber einen ganzen Zeitraum an allen möglichen Datumswerten. Dafür habe ich eine triviale Stored Function geschrieben:
-- =============================================
-- Author: Martin Cremer
-- Create date: 07.07.2015
-- Description: liefert alle Tage eines bestimmten Zeitraums
-- =============================================
CREATE FUNCTION [dbo].[f_alle_Datumswerte]
(
@von date,
@bis date
)
RETURNS
@tab TABLE
(
datum date
)
AS
BEGIN
while @von <= @bis
begin
insert into @tab select @von
set @von = dateadd(d, 1, @von)
end
RETURN
END
GO
Um einen ganzen Zeitraum nun in eine Variable des oben definierten Typs zu schreiben, geht man so vor:
DECLARE @d AS typ_Datumswerte
INSERT INTO @d
SELECT * FROM dbo.f_alle_Datumswerte(
(SELECT min(Datum) FROM Fakt_Auftragsbestand),
(SELECT max(Datum) FROM Fakt_Auftragsbestand)
)
Damit hätten wir den ersten Punkt erledigt. Kommen wir nun dazu, alle benötigten Attribute zu ermitteln. Dafür gibt es ein paar Hilfsfunktionen, deren 1. Version ich sogar am 1.1.2009 hier schon im Blog veröffentlicht hatte, und eine Funktion, die alles zusammenfasst. Zunächst die Hilfsfunktionen (auf die heutige Zeit angepasst, in der der SQL Server nativ die deutsche ISO-Woche ermitteln kann):
-- =============================================
-- Author: Martin Cremer
-- Create date: 16.8.2006
-- Description: ermittelt aus dem Datum den Wochentag (unabhängig von SET DATEFIRST): 1=Montag - 7=Sonntag
-- =============================================
CREATE FUNCTION [dbo].[getWochentag]
(
@dat date
)
RETURNS int
AS
BEGIN
DECLARE @Result int
SELECT @Result = (datepart(dw, @dat) - 1 + @@datefirst -1) % 7 +1
RETURN @Result
END
GO
CREATE FUNCTION [dbo].[getKW_Jahr](@h as date)
returns int
as
begin
return case
when datepart(isowk, @h)>50 and month(@h) = 1 then year(@h)-1
when datepart(isowk, @h)=1 and month(@h) = 12 then year(@h)+1
else year(@h)
end
end
GO
CREATE FUNCTION [dbo].[getKW_Woche](@h as date)
returns int
as
begin
return datepart(isowk, @h)
end
GO
Die geradlinige zusammenfassende Funtkion sieht dann so aus:
-- =============================================
-- Author: Martin Cremer
-- Create date: 07.07.2015
-- Description: liefert zu den übergebenen Datumswerten alle Attribute
-- =============================================
CREATE FUNCTION [dbo].[f_Datumsattribute]
(
@datumswerte as dbo.typ_Datumswerte readonly
)
RETURNS
@Ergebnis TABLE
(
Datum date NOT NULL,
[KW_ID] INT NOT NULL,
[KW_Jahr] SMALLINT NOT NULL,
[KW] NVARCHAR(10) NOT NULL,
[KW_Nr] SMALLINT NOT NULL,
[Monat_ID] INT NOT NULL,
[Monat_OhneJahr_ID] TINYINT NOT NULL,
[Monat] NVARCHAR(8) NOT NULL,
[Monat_OhneJahr] NVARCHAR(3) NOT NULL,
[Jahr] SMALLINT NOT NULL,
[Quartal_ID] SMALLINT NOT NULL,
[Quartal_OhneJahr_ID] TINYINT NOT NULL,
[Quartal_OhneJahr] NVARCHAR(50) NOT NULL,
[Quartal] NVARCHAR(50) NOT NULL,
[Wochentag_ID] int NOT NULL,
[Wochentag] nvarchar(20) NOT NULL,
[Wochentag_Kürzel] nvarchar(2) NOT NULL
)
AS
BEGIN
INSERT INTO @Ergebnis
(Datum, [KW_ID], [KW_Jahr], [KW], [KW_Nr], [Monat_ID], [Monat_OhneJahr_ID], [Monat], [Monat_OhneJahr], [Jahr],
[Quartal_ID], [Quartal_OhneJahr_ID], [Quartal_OhneJahr], [Quartal], [Wochentag_ID], [Wochentag], [Wochentag_Kürzel])
SELECT
x.datum,
x.KW_Jahr * 100 + x.KW /* 201501 für KW 01/2015*/,
x.KW_Jahr /*2015*/,
'KW ' + RIGHT('0' + CONVERT(NVARCHAR(2), x.KW), 2) + '/' + CONVERT(NVARCHAR(4), x.KW_Jahr) /* KW 01/2015*/,
x.KW /*1*/,
x.jahr * 100 + x.Monat /* 201501 für Jan 2015 */,
x.monat /* 1 */,
monate.monatsname + ' ' + CONVERT(NVARCHAR(4), x.jahr) /* Jan 2015 */,
monate.monatsname /* Jan */,
x.jahr,
x.jahr * 10 + x.quartal /* 20151 für Q1 2015 */,
x.quartal /* 1 */,
'Q' + CONVERT(NVARCHAR(1), x.quartal) /* Q1 */,
'Q' + CONVERT(NVARCHAR(1), x.quartal) + ' ' + CONVERT(NVARCHAR(4), x.jahr),
x.wochentagID,
Wochentage.Wochentagname,
Wochentage.Wochentagkurz
FROM
(SELECT [dbo].[getKW_Jahr](d.datum) AS KW_Jahr, [dbo].[getKW_Woche](d.datum) AS KW,
MONTH(d.datum) AS monat,
datepart(QUARTER, d.datum) AS quartal,
year(d.datum) AS jahr,
[dbo].[getWochentag](d.datum) as wochentagID,
d.datum
FROM @datumswerte as d) AS x
LEFT JOIN
(SELECT 1 AS monat, 'Jan' AS Monatsname UNION ALL
SELECT 2, 'Feb' UNION ALL
SELECT 3, 'Mär' UNION ALL
SELECT 4, 'Apr' UNION ALL
SELECT 5, 'Mai' UNION ALL
SELECT 6, 'Jun' UNION ALL
SELECT 7, 'Jul' UNION ALL
SELECT 8, 'Aug' UNION ALL
SELECT 9, 'Sep' UNION ALL
SELECT 10, 'Okt' UNION ALL
SELECT 11, 'Nov' UNION ALL
SELECT 12, 'Dez' ) AS monate
ON x.monat = monate.monat
LEFT JOIN
(SELECT 1 as WochentagID, 'Montag' Wochentagname, 'Mo' Wochentagkurz UNION ALL
SELECT 2, 'Dienstag', 'Di' UNION ALL
SELECT 3, 'Mittwoch', 'Mi' UNION ALL
SELECT 4, 'Donnerstag', 'Do' UNION ALL
SELECT 5, 'Freitag', 'Fr' UNION ALL
SELECT 6, 'Samstag', 'Sa' UNION ALL
SELECT 7, 'Sonntag', 'So' ) as Wochentage
ON x.wochentagID = Wochentage.WochentagID
RETURN
END
GO
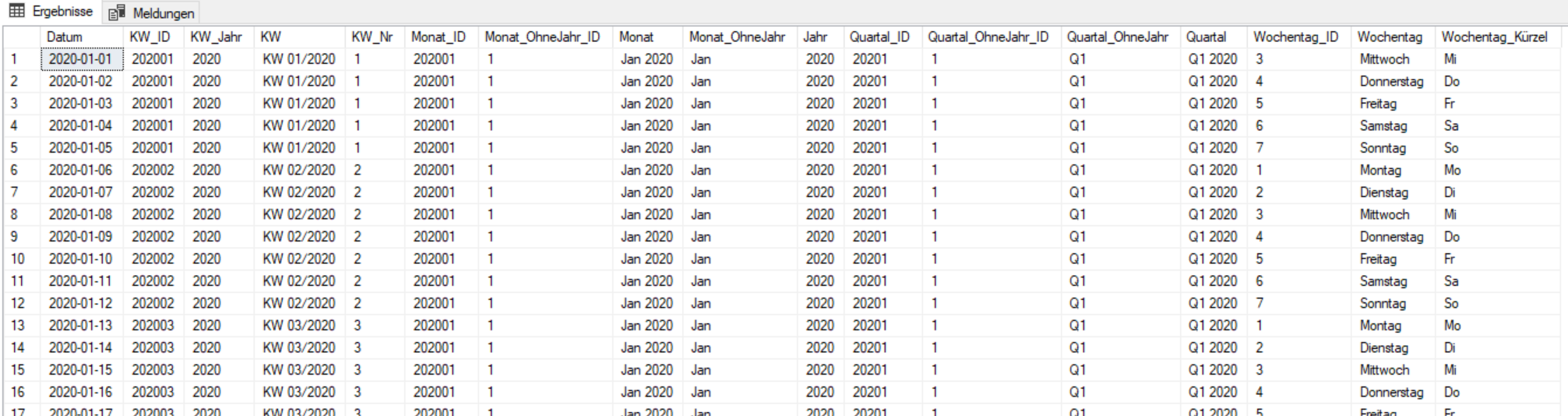
Somit kann man nun obige Ermittlung der gewünschten Datumswerte um die Ausgabe der Attribute erweitern, also zum Beispiel so:
declare @tage as [dbo].[typ_Datumswerte]
INSERT INTO @tage select * from dbo.f_alle_Datumswerte(convert(date, '1.1.2020', 104), convert(date, '31.12.' + convert(nvarchar(4), year(getdate())), 104))
select * from dbo.f_Datumsattribute(@tage)
Das Ergebnis sieht dann so aus:
Ergebnis Datumswerte
Nun müssen wir dieses SQL nur noch im SSAS ausführen lassen. Seit viele Neuerungen aus PowerBI in das Produkt SSAS einfließen, hat sich auch die Art und Weise geändert, wie man das Ergebnis von SQL-Statements im SSAS einbinden kann. Früher war es ja ganz einfach ein SQL-Statement anstelle einer Tabelle (bzw. View) zu verwenden, heute muss man wie folgt vorgehen [Die Idee dazu fand ich in Chris Webbs sehr gutem BI-Blog (hier).]:
Wenn man in Visual Studio eine neue Tabelle hinzufügt, wird im Hintergrund M-Code erzeugt, der in etwa so aussieht:
let
Source = #"SQL/<host>;<Datenbank>",
meineTabelle = Source{[Schema="dbo",Item="Beispiel"]}[Data]
in
meineTabelle
Über die Properties der Tabelle > Quelldaten > (Zum Bearbeiten klicken) kann man diesen Code einsehen.
Zu verstehen ist der Code ja ganz leicht: Über Source wird die SQL-Connection auf dem Host <host> und Datenbank <Datenbank> geöffnet. Daraus wird im obigen Beispiel die Tabelle dbo.Beispiel geladen.
Wenn wir nun obiges SQL ausführen wollen, fügen wir zunächst auf den normalen Weg im UI eine neue Tabelle hinzu (welche ist vollkommen egal). Danach bearbeiten wir dieses M-Statement zu
let
Source = #"SQL/<Host>;<Datenbank>",
Entlassungsdatum = Value.NativeQuery(
Source,
"declare @tage as [dbo].[typ_Datumswerte]
INSERT INTO @tage select * from dbo.f_alle_Datumswerte(convert(date, '1.1.2020', 104), convert(date, '31.12.' + convert(nvarchar(4), year(getdate())), 104))
select * from dbo.f_Datumsattribute(@tage)"
)
in
Entlassungsdatum
Entscheidend ist also die Änderung von Source{}[Data] zu Value.NativeQuery().
In einem Projekt hatte ich neulich die Anforderung zu kontrollieren, ob die im Integration Services Katalog auf dem SQL server enthaltenen SSIS-Pakete aktuell sind.
Bei dem Kunden gab es sehr viele Projekte und noch mehr Pakete. Dazu wurden nicht nur die Projekte als ganzes deployt (via ispac) sondern auch einzelne Pakete auch separat. Deswegen reichte es nicht die aktuelle Projekt-Version zu betrachten.
Statt dessen habe ich folgendes Statement verwendet:
use SSISDB;
with e as (
select
p.name,
xs.execution_path
,cast(xs.start_time as datetime2(0)) as start_time
,x.project_version_lsn
,p.version_build
from internal.executables x
join internal.executable_statistics xs on x.executable_id = xs.executable_id
join internal.packages p
on x.project_id = p.project_id
and x.project_version_lsn = p.project_version_lsn
and x.package_name = p.name
where
x.executable_name + '.dtsx'= x.package_name
)
select e.name, e.start_time, e.version_build
from e
where e.start_time = (select max(start_time) from e e2 Where e2.name = e.name)
order by 1
Dieses Statement liefert mir zu allen Paketen den letzte Ausführungs-Zeitstempel und die Version Build dieses Laufs. Da (bei uns) sicher war, dass die zuletzt ausgeführte Version auch die aktuelle Version war, konnte ich so die Überprüfung vereinfachen.
In diesem Artikel möchte ich beschreiben, wie man eigene Datenbank-Rollen anlegt und diesen bestimmte Rechte gibt.
Dies wird zum Beispiel benötigt, wenn man ETLs im SQL Server Agent ausführen lässt, die natürlich gewisse Rechte auf der Datenbank benötigen. Ich sehe es oft, dass die ausführenden User dann dbo-Rechte bekommen, da man (oder der Integrator) bei der Installation der Jobs nicht weiß, welche Rechte sie genau benötigen. Best practice ist natürlich, dass die ausführenden User möglichst wenig Rechte bekommen.
Ich sehe es als Entwickler-Aufgabe an, die Rollen zu erstellen und mit den nötigen Rechten auszustatten. Es ist dann die Aufgabe des Integrators, die entsprechenden User anzulegen und der Rolle zuzuordnen.
Den User kennt nämlich der Entwickler in der Regel nicht, welche Rechte er aber braucht, weiß der Integrator in der Regel nicht.
Umsetzung
In meinem Beispiel verwende ich eine Datenbank namens „Faktura“ und einen User namens „HOGWARTS\Tobias“
Das Anlegen einer Rolle ist ganz einfach – hier heißt sie „db_ETL_Verarbeitung„
use Faktura
go
CREATE ROLE [db_ETL_Verarbeitung]
GO
Nun müssen wir definieren, welche Rechte die Rolle haben soll. In unserem Beispiel soll sie
aus allen Tabellen des Schemas dbo lesen können (SELECT)
die Tabelle dbo.Spesensaetze aktualisieren dürfen (UPDATE)
und die Funktion dbo.getDatumDate ausführen dürfen (EXECUTE)
Das sind natürlich nur Beispiele, aber wenn man die Syntax kennt, findet man im Internet noch alle möglichen Beispiele.
GRANT SELECT ON SCHEMA::dbo TO [db_ETL_Verarbeitung]
GO
GRANT UPDATE ON dbo.Spesensaetze TO [db_ETL_Verarbeitung]
GO
GRANT EXECUTE ON [dbo].[getDatumDate] TO [db_ETL_Verarbeitung]
GO
Nun müssen wir nur noch den User dieser Rolle zuweisen:
ALTER ROLE [db_ETL_Verarbeitung] ADD MEMBER [HOGWARTS\Tobias]
GO
Man kann Rollen auch verschachteln. So könnte man statt obigen GRANT SELECT auf dem Schema dbo die Rolle auch zum data reader machen. Deswegen entfernen wir erst das SELECT-Recht und fügen dann die Rolle hinzu:
REVOKE SELECT ON SCHEMA::dbo TO [db_ETL_Verarbeitung]
GO
ALTER ROLE [db_datareader] ADD MEMBER [db_ETL_Verarbeitung]
GO
Vorteil
Dieses Vorgehen hat auch den Vorteil, dass man die Berechtigungen an den einzelnen Objekten (z.B. Execute auf Stored Procedures) nicht auf User-Ebene sondern auf Rollen-Ebene definiert. Das kann zum Beispiel bei Verwendung der Redgate-Tools mit eingecheckt werden. Beim Deployment auf die Produktivserver wird diese Berechtigung dann mit bereitgestellt. Nur die User-Zuordnung zur Rolle muss der Integrator/Administrator dann noch machen.
Somit ist die Entwickler- und Administratoren/Integratoren-Tätigkeit sauber getrennt.
Testen
Eine schöne Möglichkeit zu testen, ob die Rolle die richtigen Rechte hat, ist „EXECUTE AS LOGIN„.
Damit impersoniert man sich als der betreffende User (hier HOGWARTS\Tobias) und kann die Statements ausführen und sehen, ob die Rechte entsprechend vorhanden sind.
Das folgende Beispiel
execute as login = 'hogwarts\tobias'
select * from Rechnungen
update Spesensaetze
set Gruppe_id = Gruppe_id
where 1=0
update Rechnungen
set RechnungsJahr = RechnungsJahr
where 1=0
select [dbo].getDatumDate(20200101)
liefert als Ergebnis, dass die Statements 1, 2 und 4 ausgeführt werden, Statement 3 liefert
Meldung 229, Ebene 14, Status 5, Zeile 9
The UPDATE permission was denied on the object ‚Rechnungen‘, database ‚Faktura‘, schema ‚dbo‘.
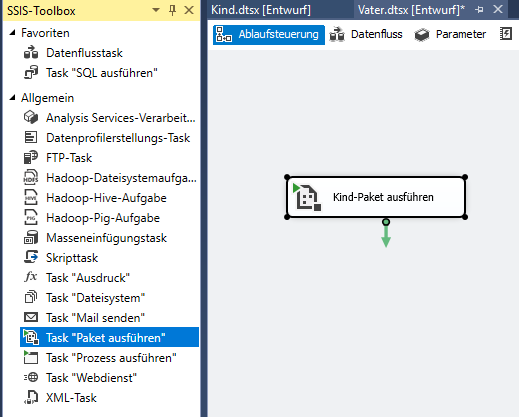
In Integration Services gibt es die Möglichkeit, aus einem Paket heraus ein Kind-Paket zu starten.
Ein Kind-Paket aufrufen
Mit Project Deployment und SQL Server 2016 geht das wunderbar.
Bei einem Kunden habe ich dieses Feature dazu genutzt, als Kind-Paket ein Paket aufzurufen, das beliebige SharePoint-Listen in die Datenbank abzieht (gesteuert durch Paketparameter, die man beim Aufruf des Kind-Pakets setzt) oder parallel aus mehreren SAP-Datenbanken Daten zusammenzusammeln.
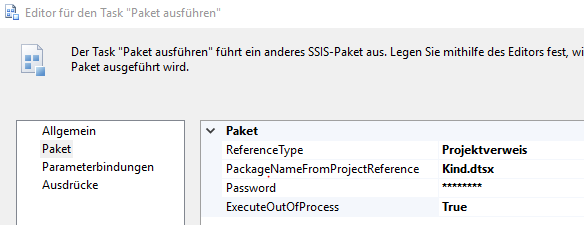
Das Feature ist an sich selbst erklärend. Ich möchte hier aber auf ein Problem eingehen, das man in einer bestimmten Konstellation hat – wenn man nämlich Execute Out Of Process auf true setzt:
Parameter „ExecuteOutOfProcess“
Dieser Parameter bewirkt, dass für die Paketausführung ein eigener Prozess gestartet wird. Dies hat den Vorteil, dass dann MultiThreading durch das Betriebssystem und nicht mehr durch SSIS gesteuert wird. (Ggf. ist auch das Verhalten bei einem Absturz besser.)
Bei meinen Tests funktionierte das wunderbar,
sowohl innerhalb von Visual Studio
als auch nach dem Deployment in die SSISDB über den SQL Server Agent
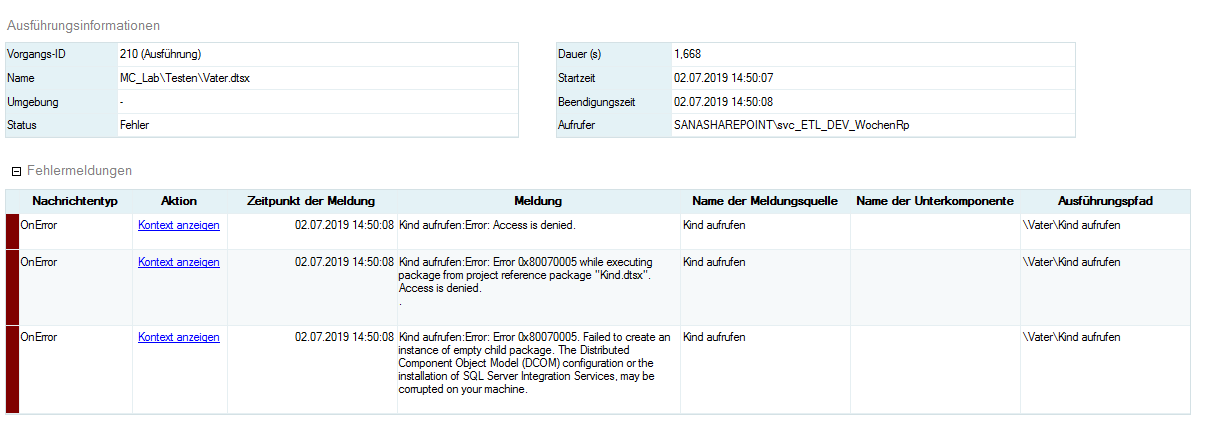
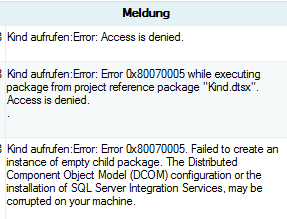
Sobald ich aber den User umstellte auf einen User, der kein Administrator war, erhielt ich folgende Fehlermeldung:
Ausschnitt aus dem Ausführungs-Bericht mit allen Meldungen
Oder genauer ein Access-Denied:
Fehlermeldungen
Da ich im Web dazu nichts gefunden habe, habe ich mich entschlossen, diesen Blog-Eintrag zu schreiben, nachdem ich die Lösung herausgefunden hatte.
Der erste Hinweis, woher der Fehler kommt, war die Fehlermeldung bzgl. DCOM. Deswegen habe ich versucht, DCOM-Fehlermeldung im Eventlog zu finden. Aber da waren keine – man muss das erst aktivieren, und das geht so:
Ich habe mich an die Anleitung in diesem Artikel gehalten. Ich zitiere hier, falls dieser Eintrag nicht mehr auffindbar ist:
Open the Windows Registry (regedit.exe)
Browse to this registry key: HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Ole
Create a new DWORD called ActivationFailureLoggingLevel with a value of ‚1‘
Create a new DWORD called CallFailureLoggingLevel with a value of ‚1‘
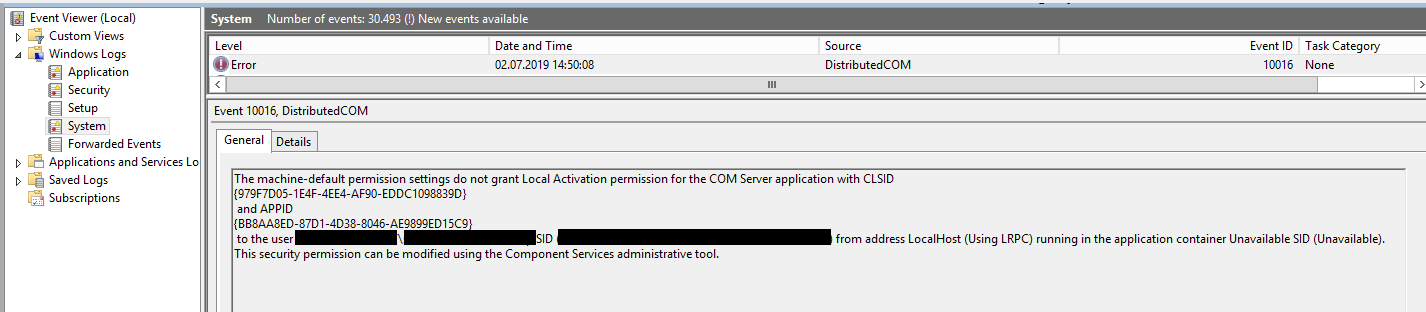
Damit war das Logging im Eventlog eingeschaltet und beim nächsten Start des SSIS-Pakets fand ich – zu der passenden Uhrzeit – im Eventlog (System) folgende Fehlermeldung:
EventlogFehlermledung im Eventlog
Man sieht also zwei GUIDs, den betroffenen User und „Local Activation“ fehlt.
Um diesen Fehler zu beheben, müssen wir erst einmal herausfinden, wozu die CLSID gehört. Dazu suchen wir in der Registry (regedit.exe) nach 979F7D05-1E4F-4EE4-AF90-EDDC1098839D und finden:
Ergebnis der Suche nach 979F7D05-1E4F-4EE4-AF90-EDDC1098839D in der Registry
Wir sehen also „Package Remote Class (64-bit)“ – „Package“ erinnert einen an SSIS-Paket. Wir sind also auf der richtigen Fährte.
Nebenbemerkung: Falls man das Paket in 32-bit ausführt, würde natürlich hier (32-bit) stehen.
Als nächstes startete ich die Component Services und klappte „DCOM Config“ auf:
Component Services (aus Administrative Tools heraus) starten DCOM Config aufklappen
Dort habe ich dann versucht, „Package Remote Class“ zu finden. Leider gibt es das aber nicht. Aber ich habe „DTS-Package Host (64-bit)“ gefunden – allerdings 3x auf diesem Server.
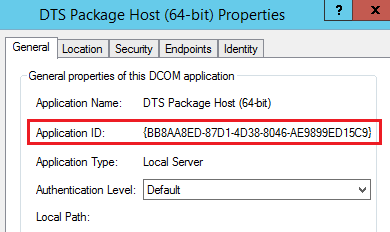
Deswegen habe ich über rechte Maustaste die Eigenschaften aufgerufen. Durch die Kontrolle der APPId (die sowohl im Eventlog als auch in der Registry steht) war ich mir sicher, die richtige Klasse gefunden zu haben:
Die Eigenschaften vom DTS Package Host auswählen …… und die Application ID mit der APP ID vergleichen.
Da es die richtige Komponente ist, wechseln wir auf den Reiter Security und stellen für den gewünschten User (der das Paket bzw. den SQL Server Agent Job ausführt) „Local Activation“ ein:
Local Activation-Rechte vergeben
Danach lief der Job bzw. das Paket ohne Fehler durch. 🙂
In einem aktuellen Projekt leiten wir Daten in eine Excel-Datei aus, um sie Benutzern – wie bisher gewohnt – zur Verfügun gzu stellen. Dabei verwenden wir als Excel-Ziel (Excel destination) eine existierende Excel-Datei (Template), in die wir auf einen Reiter in eine Tabelle Daten einfüllen .
Leider zeigt dann die Excel Destination ein ziemlich seltsames Verhalten:
Im Visual Studio funktioniert das Schreiben der Datei einwandfrei.
Richtet man einen SQL Server Agent Job ein, der in die Datei schreibt, funktioniert es mal und mal auch nicht. (Kleinere Datenmengen funktionieren, größere Datenmengen funktionieren nicht).
Dabei wird aber kein Fehler geschmissen. Das ETL läuft feherfrei durch. Zwar „sagt“ SSIS, es hätte Daten in die Datei geschrieben, aber es kommen keine Daten an.
Lasse ich den SQL Server Agent Job unter meinem Account laufen (indem ich einen Proxy anlege), so funktioniert es wieder.
Im Internet findet man etliche User, die ein ähnliches Fehlerbild haben. Bei einem Post war ein Hinweis, der mich zur Lösung brachte: https://social.msdn.microsoft.com/Forums/sqlserver/en-US/b8970522-45ac-481c-a900-14f57f37781b/excel-destination-blank-but-logging-says-it-wrote-14000-rows?forum=sqlintegrationservices
In einer Antwort wird auf diesen Artikel verwiesen: http://stackoverflow.com/questions/23523953/empty-excel-file-permissions-issue-ssis-excel-destination-buffers-large-record
Fehlerursache
Zwar entspricht dieser Post nicht meiner Situation, führte mich aber auf die richtige Fährte:
Wenn dtexec.exe unter einem nicht-angemeldeten User ausgeführt wird (wie z.B. beim Start durch den SQL Server Agent), so verwendet die Excel Destination – ab einer bestimmten Größe – eine temporäre Datei. So weit so gut. Nur leider versucht es, diese Datei unter
anzulegen. Darauf hat aber normalerweise der ausführende User keinen Zugriff.
Nachdem ich dem User Vollzugriff auf dieses Verzeichnis gegeben hatte, funtionierte es.
Vorgehen zum Finden des Fehlers
Wie im dem oben genannten Post beschrieben, habe ich auch den Process Explorer von sysinternals verwendet (Download von Microsoft-Seite).
Das Problem ist, dass man zunächst sehr viele Informationen erhält.
Filtert man dort auf den User, unter dem der ETL ausgeführt wird, ist das Bild schon üebrsichtlicher (wenn – wie bei uns – ein eigener Applikations-User verwendet wird).
Dann kann man noch die erfolgreichen Zugriffe ausblenden
(RESULT is SUCCESS –> Exclude) oder gar nur die ACCESS DENIED-Ergebnisse anzeigen
(RESULT is ACCESS DENIED –> Include)
Dann findet man es sehr schnell, wie folgender Screen Shot zeigt:
Ebenfalls interessant
Bei der Suche nach dem Fehler fand ich auch Posts, in denen die User meinten, die Excel-Datei sei leer, weil SSIS die Daten nicht oben eintrug, sondern erst nach etlichen 1000 Zeilen.
Wir hatten das gleiche Phänomen. Man muss aufpassen, dass keine Leerzeilen oben in der Datei sind. Dazu kann man einfach über Ctrl-End an das Ende springen und alle überzähligen Zeilen löschen. Somit fügt SSIS bereits die Daten oben – gut sichtbar – ein.
Nun stellt sich aber die Frage, wie man bei einer Migration von einer früheren SSAS-Version auf SSAS 2016 die dortigen Display Folder überträgt, da sie leider bei einer „normalen“ Migration via Visual Studio verloren gehen, da Visual Studio die BIDS-Helper-spezifischen Einstellungen (BIDS Helper speichert diese Informationen als Annotations in einem eigenen Format) nicht kennt.
Bei der Suche nach einer Antwort fand ich die Seite http://www.kapacity.dk/migrating-ssas-tabular-models-to-sql-server-2016-translations-and-display-folders/.
Dort wird – kurz zusammengefasst – vorgeschlagen, das neue Objekt-Modell zu verwenden, um die Display Folder zu schreiben. Das (jetzt in SSAS 2016 sehr einfache) Objekt-Modell habe ich bereits in meinem letzten Blog-Eintrag beschrieben. Der Artikel schlägt vor, die Annotations vom BIDS Helper zu parsen und daraus die zu verwendenden Display Folder zu ermitteln.
Diese Display Folder werden dann in den – bereits bereitgestellten – Cube geschrieben. Um daraus wieder eine Solution zu erhalten, muss man dann nur noch eine neue Solution aus diesem Cube erstellen.
Ich halte den Weg sehr elegant, das Objektmodell zu verwenden. Allerdings halte ich das Parsen der Annotations für unelegant und fehleranfällig. Deswegen gehe ich einen anderen Weg:
Nachdem wir den migrierten Cube deployt haben, haben wir ja zwei Cubes in unserer Umgebung:
A: der alte Cube (z.B. SSAS 2012 / 2014) mit Display Folders (BIDS)
B: der neue Cube SSAS 2016 ohne Display Folder
Nun habe ich ein einfaches SSIS-Paket erstellt, das über DMVs (Dynamic Management Views) auf den alten Cube A zugreift und für alle Measures und (echte oder berechnete) Columns die Display Folder ausliest und sie dann über das Objektmodell, wie im vorletzten Beitrag beschrieben, in den neuen Cube schreibt.
Dabei verwende ich folgende DMVs:
$SYSTEM.MDSCHEMA_MEASURES für Measures: Dort interessieren mich alle Measures (MEASURE_NAME) und ihre Display Folder (MEASURE_DISPLAY_FOLDER), sowie der MEASUREGROUP_NAME. Im Tabular Model entspricht der MEASUREGROUP_NAME dem Tabellennamen. Als Cube filtern wir auf „Model“.
$System.MDSCHEMA_HIERARCHIES für Columns: Hier interessieren mich HIERARCHY_CAPTION, HIERARCHY_DISPLAY_FOLDER. Als Cube filtern wir auf alles außer „Model“. Dies funktioniert nur in den Versionen 2012 und 2014 (aber das ist hier ja genau der Fall). Dann tauchen nämlich alle Tabellen als CUBE_NAME auf – mit vorangestellten $ (also $Currency für Tabelle Currency). Jede Spalte steht dann in HIERARCHY_CAPTION.
Zu beachten ist, dass teilweise in deutschen Versionen der Cube nicht „Model“ sondern „Modell“ heißt. Dann müssen die Abfragen natürlich entsprechend angepasst werden.
Der Code zum Aktualisieren ist dann sehr einfach:
Der neue Cube (und Server) sind Variablen im SSIS-Paket.
Der Code verbindet sich darauf und holt dann das Model in die Variable _model.
Letzlich ist der Code dann nur: Table table = _model.Tables[tableName];
if (table.Measures.Contains(measureName))
{
Measure m = table.Measures[measureName];
m.DisplayFolder = displayFolder;
}
Und zum Abschluss (also im PostExecute) werden die Änderungen auf den Server gespielt: _model.SaveChanges();
Für Columns funktioniert es analog.
Im Übrigen habe ich auf einen Fehler verzichtet, falls ein Measure oder eine Column nicht im neuen Cube B vorhanden ist. Bei uns hatte das den Hintergrund, dass wir etliche Spalten / Measures für Fremdwährungen hatten, die wir per Code erstellten, so dass sie in A vorhanden, in B aber (noch) nicht vorhanden waren. Diese nicht in B gefundenen Spalten/Measures werden von dem jeweiligen Skript ausgegeben.
Zusammenfassend gehe ich also wie folgt vor:
1. Migration der Solution auf SSAS 2016 – dadurch gehen die Display Folders verloren
2. Deploy auf einen Entwicklungs-SSAS
3. Kopieren der Display Folder von der alten Cube-Instanz auf die neue
4. Erstellen einer neuen Solution aus dem nun fertigen Cube.
Das beschriebene ETL-Paket habe ich hier als zip inkl. Solution oder hier nur als dtsx-File hochgeladen. Um es zu verwenden, muss man die beiden Variablen mit den Infos zum 2016er Cube und die Connection auf den 2012er Cube anpassen.
Nachdem sich in SSAS 2016 im Hintergrund einiges geändert hat, wird die Verarbeitung eines Cubes nun mittels JSON-Syntax und nicht mehr XMLA ausgeführt, z.B. {
"refresh": {
"type": "automatic",
"objects": [
{
"database": "AMO2016Test"
}
]
}
}
Damit wird der Cube AMO2016Test verarbeitet.
(Ein solches Skript kann man sich wie gehabt im Management Studio über den Skript-Button in den Dialogen erzeugen lassen)
Grundsätzlich verwenden wir SSIS, um solche automatisierten Tasks durchzuführen (damit wir Standard-Features wie Protokolierung, Fehlerhandling etc. nutzen können).
Die Standard-Verarbeitungs-Komponente kann man nicht verwenden, da sie XMLA-basiert ist.
Aber man kann ganz einfach obigen Code in einer Execute-SQL-Task ausführen lassen, wenn man als Connection eine OLE-DB-Connection auf den Cube angelegt hat.
Es darf einen also nicht wundern, dass man einen JSON-Code in der Execute-SQL-Task ausführt. Da aber der Code einfach durchgereicht wird, ist klar, dass es funktioniert.
In einem Projekt erstellen wir Measures dynamisch: Für Währungen, die wir in einer relationalen Tabelle eintragen, werden automatisch Währungsumrechnungen aller Umsätze durchgeführt und dann im Cube automatisch angezeigt.
In SSAS vor der Version 2016 war das sehr kompliziert, da AMO (also das Objekt-Modell, auf das man via C# zugreifen konnte) noch dem MOLAP-Modell entspricht. Dort gab es also das Konzept z.B. berechneter Spalten nicht nativ. Deswegen gab es unter CodePlex ein AMO2Tabular-Projekt, mit dem versucht wurde, den Zugriff gekapselt zu ermöglichen.
In SSAS 2016 ist alles nun viel einfacher.
Hier ein Beispiel-Code (den wir in Integration Services eingebunden haten, da wir unsere Automatisierung als Teil unserer täglichen ETLs entwickelten):
Zunächst müssen Referenzen definiert werden:
AnalysisServices.Server.Tabular.dll
AnalysisServices.Server.Core.dll
Diese DLLs habe ich aus dem GAC genommen:
C:\Windows\Microsoft.Net\assembly\GAC_MSIL\Microsoft.AnalysisServices.Tabular\v4.0_14.0….. //using System.Data; - sonst ist DataColumn nicht mehr eindeutig
using Microsoft.AnalysisServices.Tabular;
In meinem letzten Projekt hatten wir interessante Kennzahlen:
Es ging um Startzeiten von bestimmten Prozessen:
Gegeben war ein datetime-Feld “Beginn”.
Jetzt waren folgende Kennzahlen gewünscht:
Was ist der früheste Beginn?
Zum Beispiel: In der KW9 um welche Uhrzeit haben folgende Maschinen jeweils begonnen?
Maschine A: 8:00 Uhr
Maschine B: 8:30 Uhr
Maschine C: 7:30 Uhr
Wann war der durchschnittliche Beginn in einer Woche?
Zum Beispiel:
Mo 8:00 Uhr
Di 9:00 Uhr
Mi 8:30 Uhr
Do 7:00 Uhr
Fr 10:00 Uhr
ergibt einen Durchschnitt von 8:30 Uhr
Wir haben es wie folgt implementiert:
Zunächst haben wir zwei berechnete Spalten definiert:
BeginnDatum als date(year([Beginn]); month([Beginn]); DAY([Beginn]))
BeginnUhrzeit als [Beginn]-[BeginnDatum]
Damit erhalten wir die Uhrzeit ohne Datum.
Damit ist die erste Kennzahl ganz einfach:
Erster Beginn:=MIN([BeginnUhrzeit])
Und der Durchschnitt ist auch nicht schwer:
Ø Erster Beginn:=Averagex(Values(‚Fakten_Operationen'[BeginnDatum]); [Erster Beginn])
Dabei ist der erste Parameter der Averagex-Funktion die Menge der Werte, nach denen die Kennzahl berechnet werden muss und worüber dann der Durchschnitt gebildet wird.
Deswegen haben wir hier die Datumswerte mit Values(‚Fakten_Operationen'[BeginnDatum]) verwendet.
Dies lässt sich natürlich einfach verallgemeinern.
Meine Erfahrungen in der Business Intelligence Welt