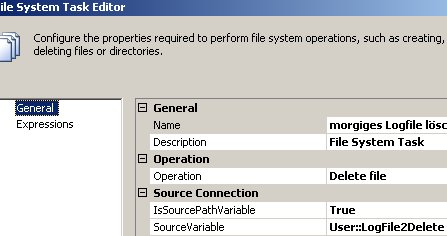
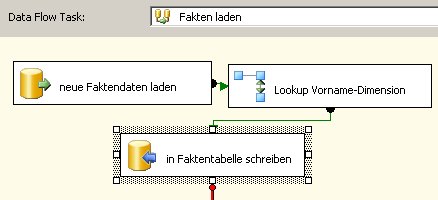
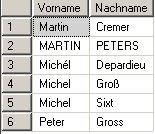
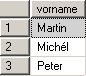
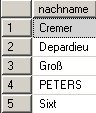
Alle Aufgaben, die man im SQL Server Management Studio für den Betrieb eines SQL Server Analysis Services vornehmen kann, können auch über XMLA gesteuert werden.
Das gilt zum Beispiel für das Aufbereiten (Verarbeiten, process) von Cubes oder dem Backup von Datenbanken. Ich werde mich heute mit dem Backup einer Analysis Services – Datenbank beschäftigen.
Das Schöne ist, dass wir gar nicht die Syntax der XMLA nachschlagen müssen. Das SQL Server Management Studio erstellt uns nämlich den notwendigen XMLA-Code automatisch (und das gilt für beide Versionen 2005 und 2008). Dazu wählen wir zunächst im Kontextmenü die gewünschte Aktion aus:
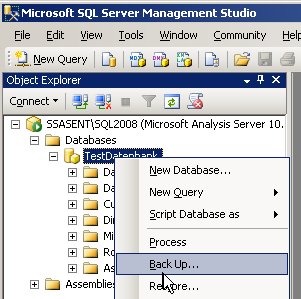
Dann startet sich ein Popup-Fenster, in dem wir die gewünschten Einstellungen durchführen, aber nicht auf OK klicken.
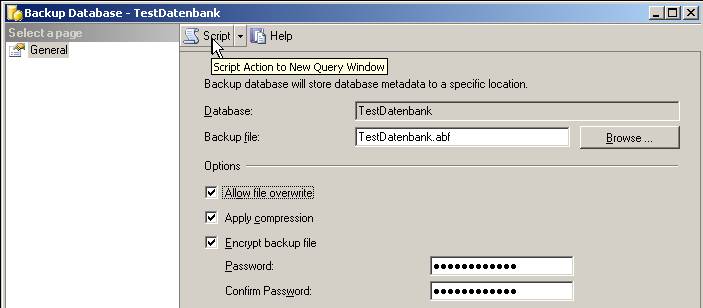
Im oberen Bereich befindet sich eine Script-Button. Wenn man auf diesen klickt, wird das zugehörige XMLA erstellt:
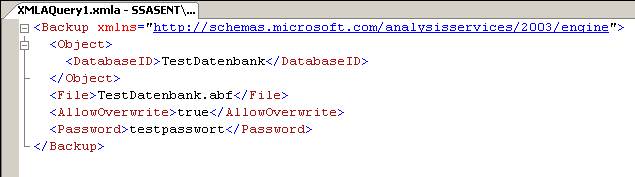
Dies kann man jetzt sogar direkt im SQL Server Management Studio ausführen (Execute!).
Bei Erfolg liefert die Ausführung folgendes Ergebnis:
<return xmlns=“urn:schemas-microsoft-com:xml-analysis“>
<root xmlns=“urn:schemas-microsoft-com:xml-analysis:empty“ />
</return>
Das Problem (auf das wir später noch zurückkommen werden) ist, dass auch bei einem Fehler in der Regel kein Fehler geschmissen wird (bei Analysis Services 2008 kommen manchmal Fehler vor), sondern ein XML zurückgegeben wird, in der die XML-Knoten Exception oder Error oder ähnliches auftauchen. Wie gesagt, dazu später mehr.
Wie können wir nun ein solches XMLA automatisiert (zeitgesteuert) aufrufen?
Die einfachste Möglichkeit ist über den SQL Server Agent. Wir legen dazu einen neuen Job an. Der erste Schritt des neuen Jobs sieht so aus:
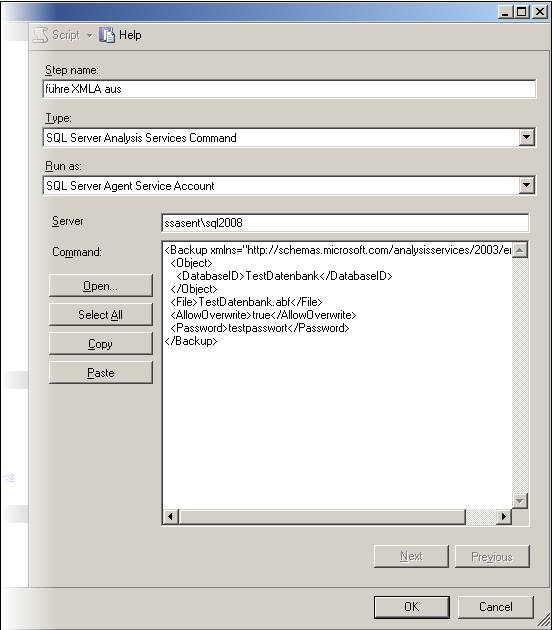
Wie man in obigem Screen Shot sieht, muss als Typ „SQL Server Analysis Services Command“ ausgewählt, als Server dergewünschte SQL Server Analysis Services-Server (hier im Beispiel ssasentsql2008) eingetragen und das XMLA in die große Textbox Command kopiert werden.
Damit kann dieses XMLA im Rahmen eines SQL Server Agent Jobs ausgeführt werden.
Im Log File Viewer kann man nach der Ausführung das ERgebnis der Ausführung wie folgt erkennen:
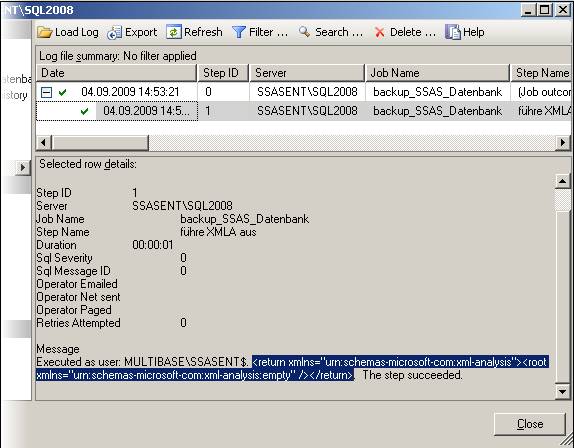
Was ich markiert habe, ist genau das Ergebnis, das wir vorhin auch als Ergebnis bei der Ausführung im SQL Server Management Studio gesehen hatten. Hier erkennt man, dass die Ausführung erfolgreich war, weil das Ergebnis „empty“ ist. Natürlich wird der Job als erfolgreich beendet angezeigt.
Das Problem hierbei ist, dass bei Fehlern bei der Ausführung der Job ebenfalls als erfolgreich abgeschlossen angezeigt wird und die Fehlermeldung nur an dieser Stelle im Log sichtbar ist.
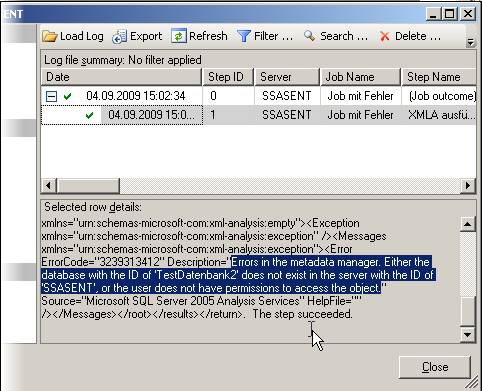
Man erkennt deutlich, dass der Step als erfolgreich markiert ist, aber offensichtlich nicht erfolgreich durchgeführt wurde. Die Fehlermeldung habe ich markiert. (In dem Beispiel handelte es sich um das Aufbereiten einer nicht existenten Datenbank)
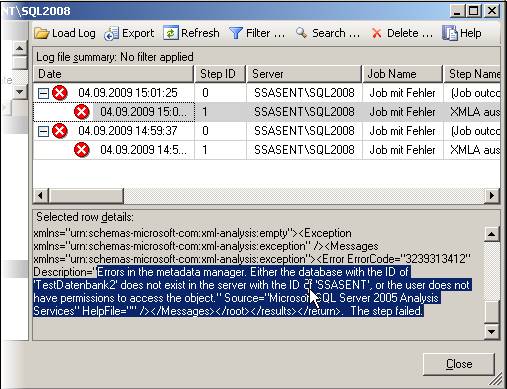
Dies ist natürlich sehr ungünstig, da Administratoren auf das Fehlschlagen eines Jobs reagieren können, aber nicht auf irgendwo enthaltene Fehlermeldungen. Deswegen empfehle ich, in produktiven Umgebungen das XMLA nicht direkt im SQL Serevr Agent auszuführen, sondern, wie gleich beschrieben im SSIS. Im SQL Server Agent 2008 scheint dieses Problem behoben zu sein. Wenn man obigen fehlerhaften Job im SQL Server Agent 2008 anlegt (sogar auch wenn man als Ziel des XMLA sogar einen 2005er Analysis Services wählt), wird der Fehler im SQL Server Agent erkannt und sinnvoll protokolliert, wie man in folgendem Screen Shot sehen kann:
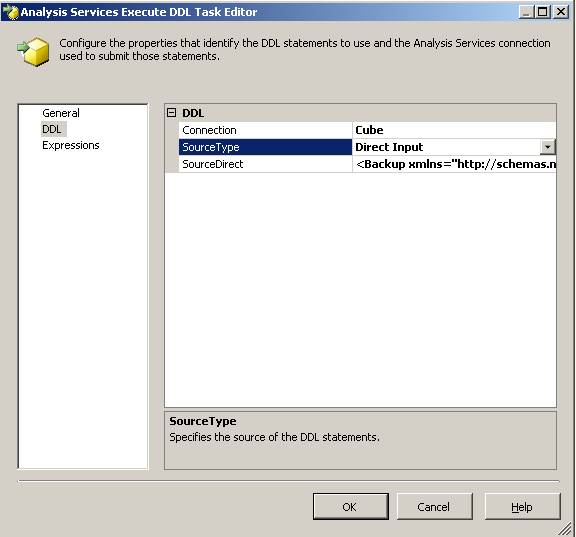
Nun aber zu einer anderen Möglichkeit, das XMLA auszuführen, als Integration Services Package im SSIS:
Im Control Flow gibt es dort eine Task mit Titel Analysis Services Execute DDL Task. Diese benötigt eine Cube-Connection und das zu automatisierende XMLA. Das XMLA kann dabei direkt eingegeben oder aus einer Variable oder aus einem File ausgelesen werden. Letzters wird bei großen XMLAs benötigt, da sonst die Größenbeschränkung auf ca. 4000 Zeichen besteht.
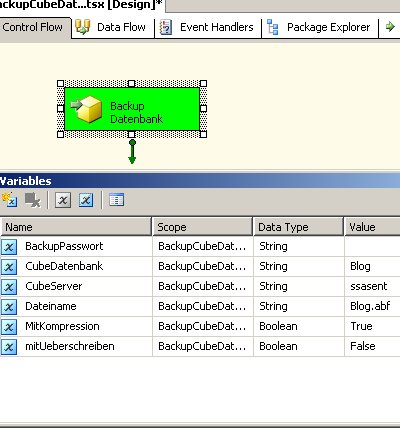
Unter diesem Link habe ich ein einfaches Paket zum Download bereit gestellt, dass nach Eingabe einiger Variablen das XMLA automatisch erstellt (über Expressions der Execute SSAS DDL Task) und dann ausführt. Die Variablen sind im beigefügten Config-File enthalten, so dass Sie das Paket auch einfach über die Anpassungen an dieser Config-Datei steuern können.
Als Variablen werden verwendet:
-
CubeDatenbank: Die SSAS-Datenbank, die gesichert werden soll.
-
CubeServer: Der Name des SSAS-Servers, auf dem sich die zu sichernde Datenbank befindet.
-
Dateiname: Name der zu erstellenden Datei
-
MitKompression: Soll die Datei komprimiert werden? (im Config-File 0 für nein, 1 für ja eintragen)
-
mitUeberschreiben: Soll evtl. eine bereiots existierende Datei überschrieben werden? (im Config-File 0 für nein, 1 für ja eintragen)
-
BackupPasswort: Geben Sie das an, wenn Sie Ihr Backup verschlüsseln wollen, sonst leer lassen (dann wird nicht mit leerem Passwort verschlüsselt 🙂 )
Ganz analog können alle XMLAs mit SSIS ausgeführt werden.