Manchmal reicht es nicht aus, feste SQL-Statements als Quelle oder bei Lookups zu hinterlegen.
Bei einer OLE-DB-Quelle kann man ganz einfach das SQL-Statement in einer Variable ablegen.
Wie man das auch bei Lookups machen kann, zeigt dieser Eintrag.
Zunächst zur Motivation:
Man könnte sich vorstellen, dass innerhalb eines Datenflusstasks immer nur Daten eines Tages in eine Tabelle geschrieben werden. Der Tag steht dabei in einer Variablen. Nun soll bei jedem Lookup überprüft werden, ob der Primary Key der Daten an diesem Tag schon in einer Tabelle steht. Da der Lookup alle Daten cacht, macht es Sinn nur die Daten des Datums aus der Variablen zu lesen.
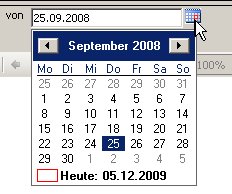
In unserem Beispiel heißt die Variable „Tag_deutsch“ und speichert das Datum als String mit deutschem Datumsformat.
Das Lookup-SQL müsste also so aussehen:
select * from ZahlenProTag
Where Tag = CONVERT(date, '7.5.2010', 104)
oder allgemein
select * from ZahlenProTag
Where Tag = CONVERT(date, '<Inhalt der Variablen Tag_deutsch>', 104)
Deswegen legen wir eine berechnete (EvaluateAsExpression:=true) Variable „Lookup-SQL“ an, mit der Expression:
"select * from ZahlenProTag
Where Tag = CONVERT(date, '" + @[User::Tag_deutsch] + "', 104)"
Jetzt bauen wir erst mal unseren Data Flow Task, noch mit dem kompletten Lookup auf ZahlenProTag:
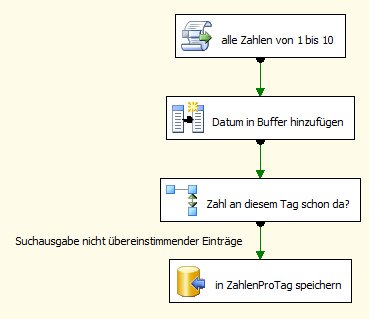
Zu den einzelnen Komponenten:
-
alle Zahlen von 1 bis 10 habe ich bereits in meinem letzten Blogeintrag verwendet (s. https://www.csopro.de/biblog/2010/04/temporaere-tabellen-in-ssis-verwenden/). Es liefert alle Zahlen von 1 bis 10
-
Eine abgeleitete Spalte mit dem Namen Datum wird hinzugefügt, mit folgender Formel:
(DT_DBDATE)@[User::Tag_deutsch]
ACHTUNG. Dabei muss als LocaleID deutsch eingestellt sein, da der String ja in deutschem Datumsformat steht -
Der Lookup sieht auf dem ersten Tab so aus:
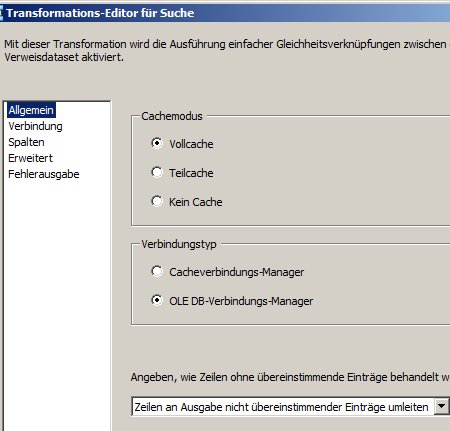
und so auf dem zweiten:
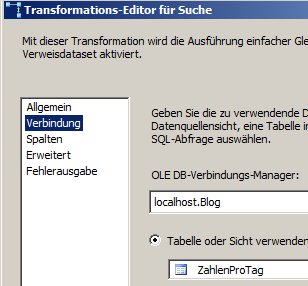
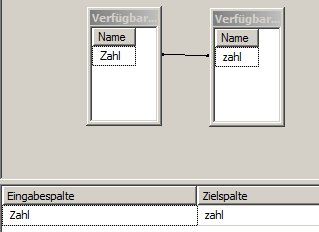
und so auf dem dritten:
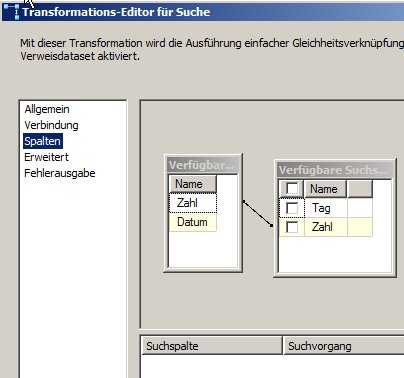
Man beachte, dass zum Lookup nur die Zahl und nicht das Datum verwendet wird.
Letzteres könnte man natürlich machen. Dann würde aber die gesamte Tabelle in den Cache geladen werden, obwohl wir wissen, dass nur ein kleiner Bruchteil benötigt wird. -
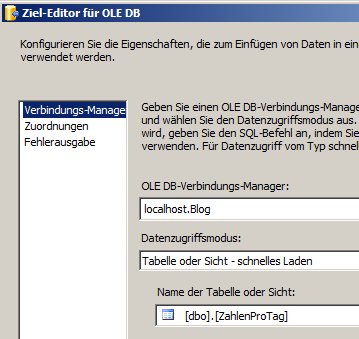
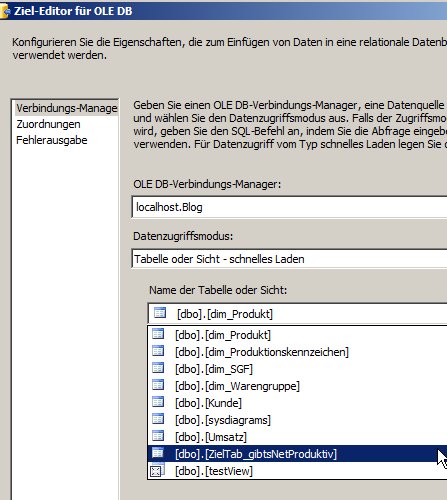
Das OLE-DB-Ziel ist wieder naheliegend:
Tab 1:
Tab 2:
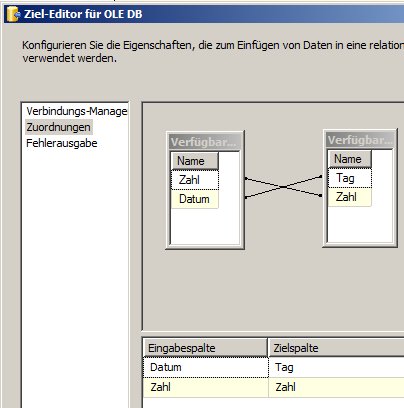
Soweit so gut.
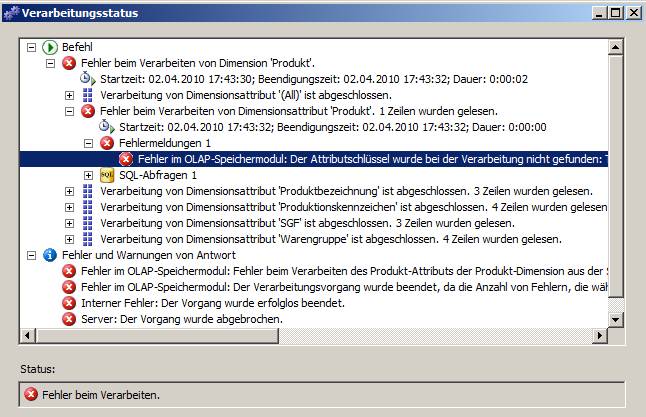
Nun wollen wir das Lookup-SQL auf die oben angelegte Variable umstellen. Dazu gehen wir in die Ablaufsteuerung / Workflow und selektieren den Datenfluss-Task, so dass wir im Eigenschaftsfenster dessen Eigenschaften sehen.
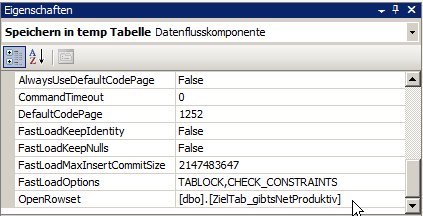
Dort fällt auf, dass es unter Sonstiges eine Eigenschaft mit dem Titel [Zahl an diesem Tag schon da?].[SqlCommand] gibt:
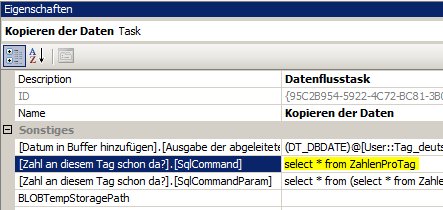
[Zahl an diesem Tag schon da?] ist ja der Name der Lookup-Komponente.
SqlCommand gibt das SQL an, das zum Befüllen des Caches verwendet wird (wir hatten ja den Standard Vollcache belassen)
SqlCommandParam würde man nur bei den anderen Cache-Typen benötigen.
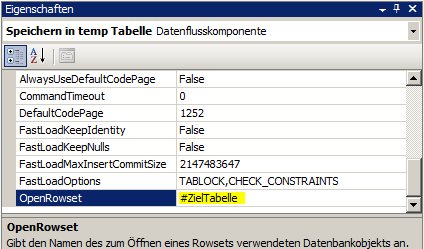
Nun können wir über Expressions des Data Flow Tasks diese Eigenschaft überschreiben:
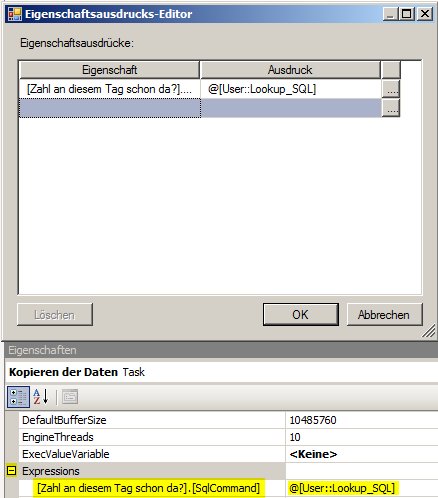
So jetzt geht’s!
Im Status bzw. Protokoll kann man kontrollieren, wieviele Zeilen der Lookup gecacht hat:
[Zahl an diesem Tag schon da? [13]] Informationen: ‚Komponente ‚Zahl an diesem Tag schon da?‘ (13)‘ hat insgesamt 0 Zeilen zwischengespeichert.
Diese Zeile kommt, wenn man die Variable auf ein neues Datum stellt.
Wenn die Variable auf einem bereits verwendeten Datum steht, kommt:
[Zahl an diesem Tag schon da? [13]] Informationen: ‚Komponente ‚Zahl an diesem Tag schon da?‘ (13)‘ hat insgesamt 10 Zeilen zwischengespeichert.
Also ist alles OK!



 klicken)
klicken) ):
):
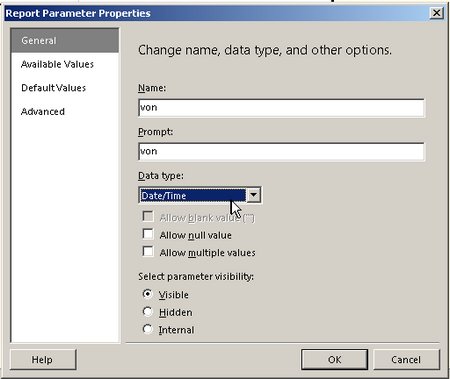
 , den wir wie folgt bearbeiten: Wir setzen den Datentyp auf Datetime:
, den wir wie folgt bearbeiten: Wir setzen den Datentyp auf Datetime: